動機
整理一些sql的用法
把SQL當成一種奇怪的PL
與awk有點像,SQL的溝通單位只有類似matrix的資料結構 不過這個matrix沒辦法用index取值
同時每家DBMS的實作又有點差別像是CTE的部分就差很多
產生matrix(table)
subquery
最基本的產生matrix的手段 最好都要替每個subquery加命名
SELECT P_Name FROM products_taiwan
WHERE P_Name NOT IN
(SELECT P_Name FROM products_china) china;
view
當成matrix的抽象
CREATE VIEW V_Customer
AS (SELECT First_Name, Last_Name, Country FROM Customer);
function (& stored procedure)
可以產生table也可以產生value
CREATE FUNCTION Sales.ufn_SalesByStore (@storeid int)
RETURNS TABLE
AS
RETURN
(
SELECT P.ProductID, P.Name, SUM(SD.LineTotal) AS 'Total'
FROM Production.Product AS P
JOIN Sales.SalesOrderDetail AS SD ON SD.ProductID = P.ProductID
JOIN Sales.SalesOrderHeader AS SH ON SH.SalesOrderID = SD.SalesOrderID
JOIN Sales.Customer AS C ON SH.CustomerID = C.CustomerID
WHERE C.StoreID = @storeid
GROUP BY P.ProductID, P.Name
);
procedure基本上就是把指令打包在一起 但沒有回傳值
CREATE PROCEDURE HumanResources.uspGetEmployeesTest2
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SELECT FirstName, LastName, Department FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName AND EndDate IS NULL;
GO
從python來看sql
assign
EmpIDVariable = max([row['EmployeeID'] for row in HumanResources.Employee])
DECLARE @EmpIDVariable int;
SELECT @EmpIDVariable = MAX(EmployeeID)
FROM HumanResources.Employee;
while
MyCounter = 0
TestTable = [] # queue
while MyCounter < 26:
TestTable.append((MyCounter,char(int('a')+MyCounter)))
MyCounter += 1
DECLARE @MyCounter int;
SET @MyCounter = 0;
WHILE (@MyCounter < 26)
BEGIN;
INSERT INTO TestTable VALUES
(@MyCounter, CHAR((@MyCounter + ASCII('a'))));
SET @MyCounter = @MyCounter + 1;
END;
cursor
基本款
vend_cursor = iter(Purchasing.Vendor)
next(vend_cursor)
DECLARE vend_cursor CURSOR
FOR SELECT * FROM Purchasing.Vendor
OPEN vend_cursor
FETCH NEXT FROM vend_cursor;
兩個iterator
為什麼要提兩個的iterator? 因為sql的has_next是變數 所以比較特別 所以再貼一個例子
vendor_id, vendor_name, message, product = (0,'','','')
print('-------- Vendor Products Report --------')
vendor_cursor = iter(sorted([{'VendorID': row['VendorID'], 'Name': row['Name']} for row in Purchasing.Vendor if row['PreferredVendorStatus'] == 1],key=lambda row: row['VendorID']))
vendor_id, vendor_name = next(vendor_cursor) # it's tedious to access each element by key, so imagine it can be done by deconstruct >_!
while has_next(vendor_cursor):
'''
In fact, WHILE @@FETCH_STATUS = 0 is euqal to while hasnext(vendor_cursor).
However, python don't have hasnext for its iterator.
Instead, python iterator will throw an exception at the end of iteration.
Here, imagine we have has_next() in python, okay.
'''
print(' ')
message = '----- Products From Vendor: ' + vendor_name
print(message)
product_cursor = iter([...]) # it's tedious to implement this, so skip it
product = next(product_cursor)
for product in product_cursor:
message = ' ' + product
# python iterator need not to be deallocated, after it accomplish its purpose
vendor_id, vendor_name = next(vendor_cursor)
# python iterator need not to be deallocated, after it accomplish its purpose
DECLARE @vendor_id int, @vendor_name nvarchar(50),
@message varchar(80), @product nvarchar(50);
PRINT '-------- Vendor Products Report --------';
DECLARE vendor_cursor CURSOR FOR
SELECT VendorID, Name
FROM Purchasing.Vendor
WHERE PreferredVendorStatus = 1
ORDER BY VendorID;
OPEN vendor_cursor
FETCH NEXT FROM vendor_cursor
INTO @vendor_id, @vendor_name
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT ' '
SELECT @message = '----- Products From Vendor: ' + @vendor_name
PRINT @message
DECLARE product_cursor CURSOR FOR
SELECT v.Name
FROM Purchasing.ProductVendor pv, Production.Product v
WHERE pv.ProductID = v.ProductID AND
pv.VendorID = @vendor_id -- Variable value from the outer cursor
OPEN product_cursor
FETCH NEXT FROM product_cursor INTO @product
IF @@FETCH_STATUS <> 0
PRINT ' <<None>>'
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT @message = ' ' + @product
PRINT @message
FETCH NEXT FROM product_cursor INTO @product
END
CLOSE product_cursor
DEALLOCATE product_cursor
FETCH NEXT FROM vendor_cursor INTO @vendor_id, @vendor_name
END
CLOSE vendor_cursor;
DEALLOCATE vendor_cursor;
case
有趣的部份是除了回傳data外,還可以回傳column name
SELECT OrderID, Quantity,
CASE
WHEN Quantity > 30 THEN 'The quantity is greater than 30'
WHEN Quantity = 30 THEN 'The quantity is 30'
ELSE 'The quantity is under 30'
END AS QuantityText
FROM OrderDetails;
SELECT CustomerName, City, Country
FROM Customers
ORDER BY
(CASE
WHEN City IS NULL THEN Country
ELSE City
END);
遞迴 (table as queue)
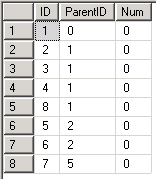
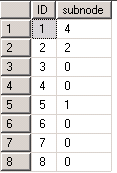 When we iterate a tbale in sql, the only element we can access is the first row of its table.
And then, the second, the third and so on.
When we iterate a tbale in sql, the only element we can access is the first row of its table.
And then, the second, the third and so on.
When we want to insert a new row to a table, this row will be inserted at the tail of the table.
Wait, it’s like something we are familiar with.
Queue!!
WITH node AS --queue declare
(
SELECT id,parentid,num FROM testtable AS TREE
WHERE parentid = 0 UNION ALL /* init argument where we start bfs */
-- enqueue the neighbors
SELECT TREE.id,TREE.parentid,TREE.num FROM testtable AS TREE
INNER JOIN node AS QUEUE
ON QUEUE.id = TREE.parentid /*從bfs的節點找下一個node,推到queue*/
)
SELECT QUEUE.id,Count(TREE.id) AS subnode FROM node AS QUEUE
LEFT JOIN testtable AS TREE ON QUEUE.id = TREE.parentid
GROUP BY QUEUE.id
最短路徑
WITH paths (node, path, cost, rnk, lev) AS ( -- priority queue
SELECT a.dst, a.src || ',' || a.dst, a.distance, 1, 1
FROM arcs a
WHERE a.src = :SRC
UNION ALL
SELECT a.dst,
p.path || ',' || a.dst,
p.cost + a.distance,
Rank () OVER (PARTITION BY a.dst ORDER BY p.cost + a.distance), -- tree被更新就sort一次quere(part of this table)
p.lev + 1
FROM paths p
JOIN arcs a
ON a.src = p.node
AND p.rnk = 1
) SEARCH DEPTH FIRST BY node SET line_no -- oracle DB的CTE特別語法: 用什麼方式traversal -- 這邊改成bfs應該沒關係,但沒試驗過
CYCLE node SET lp TO '*' DEFAULT ' ' -- oracle DB的CTE特別語法: 要判斷cycle
-- 上面把所有路線都展開,在展開同時對目前找到的做sort
, paths_ranked AS (
SELECT lev, node, path, cost, Rank () OVER (PARTITION BY node ORDER BY cost) rnk_t, lp, line_no
FROM paths
WHERE rnk = 1
)
-- 從每個queue挑出最好的結果
SELECT LPad (node, 1 + 2* (lev - 1), '.') node, lev, path, cost, lp
FROM paths_ranked
WHERE rnk_t = 1
ORDER BY line_no
-- print result