動機
當初看這本是想補完一些linux kernel的設計實做,但最後發現除了第一章之外,都是code加直譯code的中文…
這樣與自己trace有什麼區別!?
code只是設計的其中一種體現 書的重點應該是介紹設計,再加上一些比較特別或是重要的code
所以後面就改成挑經典概念(不同於xv6)的解釋
ch4是說lock的實做,所以挑RCU來說 ch5是說中斷的,可以參考linux kernel development與xv6的pdf ch6是怎麼debug像ftrace與debugfs、systemtap、kasan、kmemleak、CONFIG_DEBUG_LOOKDEP
page: buddy
原本在xv6是直接從freelist拿一個page,但這樣一直alloc與free,會讓連續的page變少
所以buddy就是先設定好一定大小的page,組成block,之後就是從對應的長度取
如果差一點點,就是把剩下的丟到對應的長度,例
3 pages從$2^2$拿一塊,剩下1page放到$2^0$
object: slab
一次拿一個page真的很大,很多時候只要放struct而已,所以有了slab
給定struct大小,之後裡面切成3個list,剩下就與freelist很像,但是單位是struct大小
- full: page被占滿
- partial: 有空的、有被用的
- free: 都空的

想知道slab的訊息可以參考這裡
rmap
我們有mmap,把va對到pa rmap就是讓pa知道有多少va對到他,這樣就能從pa做unmap了
kswapd就會用到rmap,另外在memory compact做memory migrate(把page移到另一個process)也會用到rmap
gc: kswapd
kswapd就是負責回收page(像是slab的page)的kernel process
基本上觸發條件與gc差不多
- 週期性
- 當碰到zone(linux描述mem的資料結構)的low watermark
為什麼我們要free?
因為kernel沒有辦法確認這mem還有沒有人要用到。
ptr其實就是整數,但kernel不知道這塊mem是不是有人指到。
這樣就乾脆讓user自己管理就好。 但是現在大部分語言都會把object抽象出來,這樣就能利用object本身的struct紀錄使用情況,來做gc
memory compact
buddy可以降低fragmentation的衝擊,但最後一定會有,所以還是要處理
所以才有memory compact,基本上就是一邊找可以移動的page,一邊找空的page,之後migrate

詳細可以看這邊
kernel same page
把page當成key,做比對,之後遇到一樣的page就能共用
像是開了許多linux vm這樣應該有一些page的內容會是一樣的

OOM
malloc是申請(commit),說有這一塊可以用(看xv6 lazy allocation與cow)
但通常user不會剛好把申請全部用完,這樣其實很浪費
所以linux認可某種程度上的overcommit
可以用/proc/sys/vm/overcommit_memory調overcommit的行為
如果真的pa都沒了,連kernel的free都給完了,oom killer就會出現,找一個proc下手
可以透過/proc/<pid>/oom_score調oom分數,讓killer盡量不會對某些proc下手
RCU
RCU就是不用lock做出來的的rwlock
RCU可以當成一個ptr的buffer
updater做好修改後,synchronize_rcu會等其他reader讀完 之後就會把新的ptr丟出去,最後把舊的回收掉
void foo_read(void) {
rcu_read_lock();
foo *fp = global_foo;
if (fp)
do_something(fp->a, fp->b, fp->c);
rcu_read_unlock();
}
void foo_update(foo *new_fp) {
spin_lock(&foo_mutex);
foo *old_fp = global_foo;
global_foo = new_fp;
spin_unlock(&foo_mutex);
synchronize_rcu();
kfree(old_fp);
}


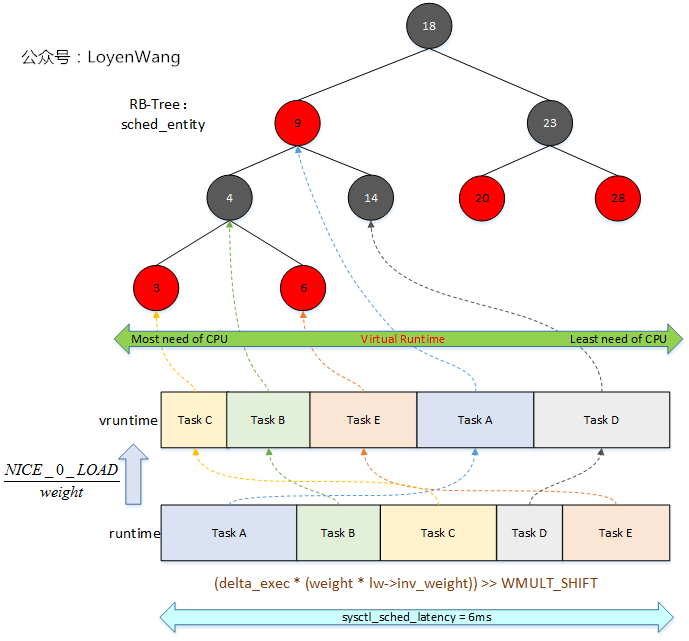
cfs schedule
把每個proc當成有一個cpu,所以假設每個proc都完美的同時跑的話,每個proc的執行時間應該一樣長
cfs就是多一個vruntime去模擬每個proc的執行時間,每次挑都挑最少vruntime的
如果要sort又要支援找出最小,heap 而剛好linux實作rbtree可以用
算vruntime也很簡單$execDelta*(wieght/totalWieght)$ 實際上的執行時間乘上proc比重的比值,只是kernel中最好不用除法所以要改成用乘的
Ref
Linux 核心設計: 記憶體管理 Linux内核内存管理算法Buddy和Slab linux 的swap、swappiness及kswapd原理 【原创】(十五)Linux内存管理之RMAP Linux OOM killer机制介绍 Linux 核心設計: RCU 同步機制 【原创】(五)Linux进程调度-CFS调度器 理解LINUX的MEMORY OVERCOMMIT 内存管理