動機
不可多得的一本書,把所有與DB與distrubuted computing的手法與議題都說了一遍
有簡中翻譯
第一章 可靠性,可伸縮性,可維護性
應用分成
- 數據密集型的,如果數據是其主要挑戰
- 計算密集型,即處理器速度是其瓶頸
這裡談數據密集型,他們會需要
- 存儲數據,以便自己或其他應用程序之後能再次找到 (數據庫,即 databases)
- 記住開銷昂貴操作的結果,加快讀取速度(緩存,即 caches)
- 允許用戶按關鍵字搜索數據,或以各種方式對數據進行過濾(搜索索引,即 search indexes)
- 向其他進程發送消息,進行異步處理(流處理,即 stream processing)
- 定期處理累積的大批量數據(批處理,即 batch processing)
有3個重點
- 可靠性(Reliability)
- 系統在困境(adversity,比如硬件故障、軟件故障、人為錯誤)中仍可正常工作(正確完成功能,並能達到期望的性能水準)
- 正常工作
- 可靠性粗略理解為“即使出現問題,也能繼續正確工作”
- 設計容錯機制以防因故障而導致失效
- 故障通常定義為系統的一部分狀態偏離其標準
- 失效則是系統作為一個整體停止向用戶提供服務
- 通過故意觸發來提高故障率是有意義的
- 例如:在沒有警告的情況下隨機地殺死單個進程。
- 許多高危漏洞實際上是由糟糕的錯誤處理導致的
- Netflix公司的Chaos Monkey
- 例如:在沒有警告的情況下隨機地殺死單個進程。
- 比起阻止錯誤(prevent error),我們通常更傾向於容忍錯誤
- 硬件故障
- 為了減少系統的故障率,第一反應通常都是增加單個硬件的冗余度
- 硬件冗余對於大多數應用來說已經足夠了,它使單台機器完全失效變得相當罕見
- 只要你能快速地把備份恢覆到新機器上,故障停機時間對大多數應用而言都算不上災難性的
- 但是隨著數據量和應用計算需求的增加,越來越多的應用開始大量使用機器,這會相應地增加硬件故障率
- 類似亞馬遜AWS(Amazon Web Services)的一些雲服務平台上,虛擬機實例不可用卻沒有任何警告也是很常見的
- 雲平台的設計就是優先考慮靈活性(flexibility) 和彈性(elasticity),而不是單機可靠性
- 類似亞馬遜AWS(Amazon Web Services)的一些雲服務平台上,虛擬機實例不可用卻沒有任何警告也是很常見的
- 為了減少系統的故障率,第一反應通常都是增加單個硬件的冗余度
- 軟件錯誤
- 例子
- 接受特定的錯誤輸入,便導致所有應用服務器實例崩潰的BUG。例如2012年6月30日的閏秒
- 失控進程會用盡一些共享資源,包括CPU時間、內存、磁盤空間或網絡帶寬
- 軟件故障的BUG通常會潛伏很長時間,直到被異常情況觸發為止。
- 這種情況意味著軟件對其環境做出了某種假設
- 雖然這種假設通常來說是正確的,但由於某種原因最後不再成立了
- 這種情況意味著軟件對其環境做出了某種假設
- 軟件中的系統性故障沒有速效藥,但我們還是有很多小辦法
- 仔細考慮系統中的假設和交互;徹底的測試;進程隔離;允許進程崩潰並重啟;測量、監控並分析生產環境中的系統行為。
- 如果系統能夠提供一些保證(例如在一個消息隊列中,進入與發出的消息數量相等),那麽系統就可以在運行時不斷自檢
- 例子
- 人為錯誤
- 以最小化犯錯機會的方式設計系統
- 精心設計的抽象
- 如果接口限制太多,人們就會忽略它們的好處而想辦法繞開
- 將人們最容易犯錯的地方與可能導致失效的地方解耦(decouple)
- 特別是提供一個功能齊全的非生產環境沙箱(sandbox)
- 在各個層次進行徹底的測試
- 允許從人為錯誤中簡單快速地恢覆,以最大限度地減少失效情況帶來的影響
- 配置詳細和明確的監控,比如性能指標和錯誤率
- 精心設計的抽象
- 以最小化犯錯機會的方式設計系統
- 硬件故障
- 正常工作
- 系統在困境(adversity,比如硬件故障、軟件故障、人為錯誤)中仍可正常工作(正確完成功能,並能達到期望的性能水準)
- 可伸縮性(Scalability)
- 有合理的辦法應對系統的增長(數據量、流量、覆雜性)。
- 描述負載
- 在討論增長問題(如果負載加倍會發生什麽?)前,首先要能簡要描述系統的當前負載
- 參數的最佳選擇取決於系統架構 (例子)
- 每秒向Web服務器發出的請求
- 數據庫中的讀寫比率
- 聊天室中同時活躍的用戶數量
- 緩存命中率或其他東西
- 參數的最佳選擇取決於系統架構 (例子)
- 在討論增長問題(如果負載加倍會發生什麽?)前,首先要能簡要描述系統的當前負載
- 描述性能
- 一旦系統的負載被描述好,就可以研究當負載增加會發生什麽
- 增加負載參數並保持系統資源(CPU、內存、網絡帶寬等)不變時,系統性能將受到什麽影響?
- 增加負載參數並希望保持性能不變時,需要增加多少系統資源?
- 例子
- 批處理系統,通常關心的是吞吐量(throughput)
- 理想情況下,批量作業的運行時間是數據集的大小除以吞吐量。
- 在實踐中由於數據傾斜(數據不是均勻分布在每個工作進程中),需要等待最慢的任務完成,所以運行時間往往更長
- 對於在線系統,通常更重要的是服務的響應時間(response time)
- 響應時間可能會有很大差異。
- 因此我們需要將響應時間視為一個可以測量的數值分布(distribution)
- 而不是單個數值
- 百分位點(percentiles)
- 然而如果你想知道“典型(typical)”響應時間,那麽平均值並不是一個非常好的指標
- 因為它不能告訴你有多少用戶實際上經歷了這個延遲
- 選50百分點(中位數)
- 為了弄清異常值有多糟糕,可以看看更高的百分位點,例如第95、99和99.9百分位點
- 響應時間的高百分位點(也稱為尾部延遲,即tail latencies)非常重要,因為它們直接影響用戶的服務體驗
- 排隊延遲(queueing delay) 通常占了高百分位點處響應時間的很大一部分。
- 由於服務器只能並行處理少量的事務(如受其CPU核數的限制)
- 只要有少量緩慢的請求就能阻礙後續請求的處理,這種效應有時被稱為 頭部阻塞(head-of-line blocking)
- 由於服務器只能並行處理少量的事務(如受其CPU核數的限制)
- 然而如果你想知道“典型(typical)”響應時間,那麽平均值並不是一個非常好的指標
- 因此我們需要將響應時間視為一個可以測量的數值分布(distribution)
- 響應時間可能會有很大差異。
- 批處理系統,通常關心的是吞吐量(throughput)
- 一旦系統的負載被描述好,就可以研究當負載增加會發生什麽
- 可維護性(Maintainability)
- 許多不同的人(工程師、運維)在不同的生命周期,都能高效地在系統上工作(使系統保持現有行為,並適應新的應用場景)
- 可操作性:人生苦短,關愛運維
- deploy, monitor, update, nice infra, predictable
- 簡單性:管理覆雜度
- 覆雜度
- 額外覆雜度
- 由具體實現中湧現,而非(從用戶視角看,系統所解決的)問題本身固有的覆雜度
- 消除額外覆雜度的最好工具之一是抽象(abstraction)
- 一個好的抽象可以將大量實現細節隱藏在一個幹凈,簡單易懂的外觀下面
- 額外覆雜度
- 覆雜度
- 可演化性:擁抱變化
第二章 數據模型與查詢語言
數據模型們的影響如此深遠:不僅僅影響著軟件的編寫方式,而且影響著我們的解題思路
多數應用使用層層疊加的數據模型構建。 對於每層數據模型的關鍵問題是:它是如何用低一層數據模型來表示的
- 關系模型
- scenario
- 事務處理
- 批處理
- 對象關系不匹配
- 如果數據存儲在關系表中,那麽需要一個笨拙的轉換層,處於應用程序代碼中的對象和表,行,列的數據庫模型之間
- 一對多的關系 (適合文件型)
- SQL的作法
- 正規化與外鍵
- 放JSON
- 在col中
- encode成string
- 文件的做法
- 用JSON存
- JSON表示比正規化與外鍵的多表模式具有更好的局部性(locality
- 用JSON存
- SQL的作法
- 多對一和多對多的關系 (適合SQL)
- 會共用資料!!
- 用一個ID代表共用資料
- 各個簡介之間樣式和拼寫統一
- 避免歧義(例如,如果有幾個同名的城市)
- 易於更新——名稱只存儲在一個地方,如果需要更改(例如,由於政治事件而改變城市名稱),很容易進行全面更新。
- 本地化支持——當網站翻譯成其他語言時,標準化的列表可以被本地化,使得地區和行業可以使用用戶的語言來顯示
- 更好的搜索——例如,搜索華盛頓州的慈善家就會匹配這份簡介,因為地區列表可以編碼記錄西雅圖在華盛頓這一事實(從“Greater Seattle Area”這個字符串中看不出來)
- ID對人類沒有任何意義,因而永遠不需要改變:ID可以保持不變,即使它標識的信息發生變化。
- 用一個ID代表共用資料
- SQL的作法
- 正規化與外鍵
- 文件的做法
- 進行多個查詢來模擬join
- 複製到每個有連到的地方 (反正規)
- 即便應用程序的最初版本適合無連接的文檔模型,隨著功能添加到應用程序中,數據會變得更加互聯
- 會共用資料!!
- 一對多的關系 (適合文件型)
- 如果數據存儲在關系表中,那麽需要一個笨拙的轉換層,處於應用程序代碼中的對象和表,行,列的數據庫模型之間
- scenario
- 文檔模型 & 關系模型
- 關系模型
- 為連接提供更好的支持
- 支持多對一和多對多的關系
- 文檔模型
- 架構靈活性
- 大多數文檔數據庫以及關系數據庫中的JSON支持都不會強制文檔中的數據采用何種模式
- 沒有模式意味著可以將任意的鍵和值添加到文檔中 (讀時模式(即schema-on-read)
- 當讀取時,客戶端對無法保證文檔可能包含的字段
- 因為讀取數據的代碼通常假定某種結構——即存在隱式模式,但不由數據庫強制執行
- 集合中的項目並不都具有相同的結構時,讀時模式更具優勢
- SQL在改schema時需要migration
- 因局部性而擁有更好的性能
- 局部性僅僅適用於同時需要文檔絕大部分內容的情況
- 因此,通常建議保持相對小的文檔,並避免增加文檔大小的寫入
- 局部性僅僅適用於同時需要文檔絕大部分內容的情況
- 對於某些應用程序而言更接近於應用程序使用的數據結構
- 架構靈活性
- 關系模型
- 圖數據模型
- 關系模型可以處理多對多關系的簡單情況
- 但是隨著數據之間的連接變得更加覆雜,將數據建模為圖形顯得更加自然
- 特點
- 任何頂點都可以有一條邊連接到任何其他頂點。沒有模式限制哪種事物可不可以關聯。
- 給定任何頂點,可以高效地找到它的入邊和出邊,從而遍歷圖,即沿著一系列頂點的路徑前後移動。
- 通過對不同類型的關系使用不同的標簽,可以在一個圖中存儲幾種不同的信息,同時仍然保持一個清晰的數據模型。
- 關系模型可以處理多對多關系的簡單情況
第三章:存儲與檢索
程序員
- 數據模型: 將數據錄入數據庫的格式
- 查詢語言: 再次要回數據的機制
數據庫
索引與物化視圖:如何在我們需要時重新找到數據
編碼(第四章)與儲存方式: 數據庫如何存儲我們提供的數據
驅動數據庫的數據結構
- key & value
索引(index)
- 為了高效查找數據庫中特定鍵的值
- 任何類型的索引通常都會減慢寫入速度
- 因為每次寫入數據時都需要更新索引
- 種類
- hash index
- 保留一個內存中的散列映射,其中每個鍵都映射到數據文件中的一個字節偏移量
- 在硬盤上通過一次硬盤查找操作來加載所需部分 (seek)
- 有新index就直接append這update記錄到log去 (持久化)
- 將日志分為特定大小的段(segment)
- 當日志增長到特定尺寸時關閉當前段文件,並開始寫入一個新的段文件
- 對這些段進行壓縮(compaction)
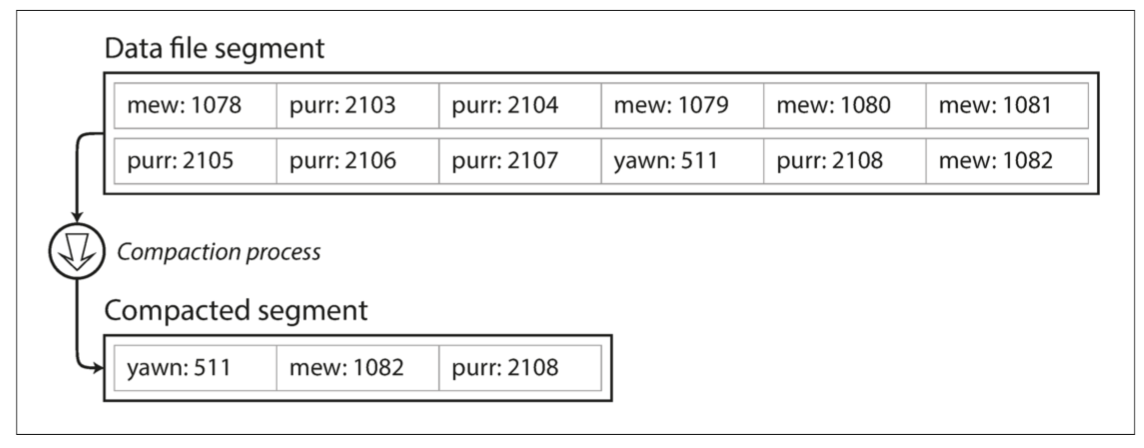
- 關於log要考慮
- 文件格式
- CSV不是日志的最佳格式。使用二進制格式更快,更簡單
- 刪除記錄
- 如果要刪除一個鍵及其關聯的值,則必須在數據文件中追加一個特殊的刪除記錄(邏輯刪除)
- 當日志段被合並時,合並過程會通過這個墓碑知道要將被刪除鍵的所有歷史值都丟棄掉
- 崩潰恢覆
- 你可以通過從頭到尾讀取整個段文件並記錄下來每個鍵的最近值來恢覆每個段的散列映射 (如果太大)
- 每個段的散列映射的快照存儲在硬盤上來加速恢覆,可以使散列映射更快地加載到內存中
- 部分寫入記錄
- 數據庫隨時可能崩潰,包括在將記錄追加到日志的過程中
- 校驗和,允許檢測和忽略日志中的這些損壞部分
- 數據庫隨時可能崩潰,包括在將記錄追加到日志的過程中
- 並發控制
- 由於寫操作是以嚴格的順序追加到日志中的,所以常見的實現是只有一個寫入線程
- 數據文件段是僅追加的或者說是不可變的,所以它們可以被多個線程同時讀取
- 文件格式
- log只append的好處
- 追加和分段合並都是順序寫入操作,通常比隨機寫入快得多
- 如果段文件是僅追加的或不可變的,並發和崩潰恢覆就簡單多了
- 合並舊段的處理也可以避免數據文件隨著時間的推移而碎片化的問題
- 缺點
- 散列表必須能放進內存
- 範圍查詢效率不高
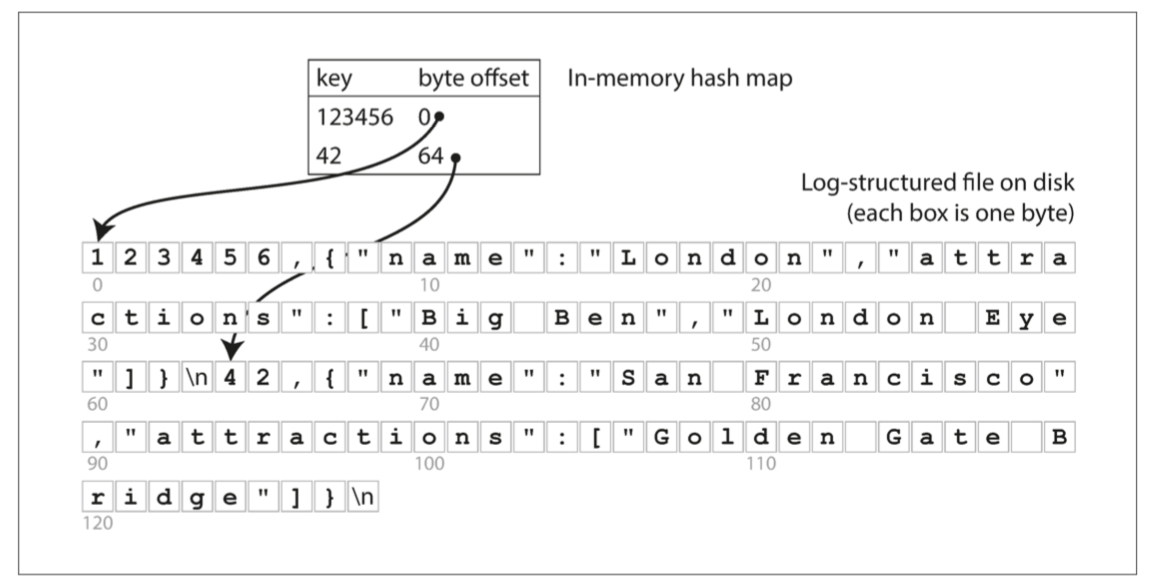
- 保留一個內存中的散列映射,其中每個鍵都映射到數據文件中的一個字節偏移量
- SSTables和LSM樹
- 前提
- 要求log的鍵值對的序列按鍵排序
- 在mem用AVL tree
- 等size夠大就dump到log
- 要求每個鍵只在每個合並的段文件中出現一次
- 要求log的鍵值對的序列按鍵排序
- 崩潰恢覆
- 多一個操作log (超常見手法)
- 好處
- 即使文件大於可用內存,合並段的操作仍然是簡單而高效的
- 為了在文件中找到一個特定的鍵,你不再需要在內存中保存所有鍵的索引
- 可以在mem存一個一個區段,之後就是在對的區段直接掃描
- 由於讀取請求無論如何都需要掃描所請求範圍內的多個鍵值對,因此可以將這些記錄分組為塊(block),並在將其寫入硬盤之前對其進行壓縮
- 省空間、io
- 缺點
- 當查找數據庫中不存在的鍵時,LSM樹算法可能會很慢
- 使用額外的布隆過濾器(Bloom filters)
- 告訴DB是不是不存在某個鍵
- 使用額外的布隆過濾器(Bloom filters)
- 當查找數據庫中不存在的鍵時,LSM樹算法可能會很慢
- 前提
- B樹
- 具有n個鍵的B樹總是具有 O(log n) 的深度
- 崩潰恢覆
- B樹的基本底層寫操作是用新數據覆寫硬盤上的頁面
- B樹實現通常會帶有一個額外的硬盤數據結構
- 預寫式日志(WAL,即write-ahead log) (超常見手法)
- B樹實現通常會帶有一個額外的硬盤數據結構
- B樹的基本底層寫操作是用新數據覆寫硬盤上的頁面
- 優化
- 使用寫時覆制 (持久化)
- 我們可以通過不存儲整個鍵,而是縮短其大小,來節省頁面空間
- 盡量使葉子頁面按順序出現在硬盤上
- LSM樹在合並過程中一次又一次地重寫存儲的大部分,所以它們更容易使順序鍵在硬盤上彼此靠近
- 額外的指針已被添加到樹中
- 每個葉子頁面可以引用其左邊和右邊的兄弟頁面
- 使得不用跳回父頁面就能按順序對鍵進行掃描
- hash index
- 比較B樹和LSM樹
- 通常LSM樹的寫入速度更快,而B樹的讀取速度更快
- LSM樹上的讀取通常比較慢,因為它們必須檢查幾種不同的數據結構和不同壓縮(Compaction)層級的SSTables
- LSM樹的優點
- 較低的寫放大 & 更高的寫入吞吐量
- 寫放大: 在數據庫的生命周期中每次寫入數據庫導致對硬盤的多次寫入
- B樹索引中的每塊數據都必須至少寫入兩次
- 一次寫入預先寫入日志(WAL)
- 一次寫入樹頁面本身
- 由於反覆壓縮和合並SSTables,日志結構索引也會多次重寫數據
- 順序地寫入緊湊的SSTable文件而不是必須覆寫樹中的幾個頁面
- LSM樹可以被壓縮得更好,因此通常能比B樹在硬盤上產生更小的文件
- 較低的寫放大 & 更高的寫入吞吐量
- LSM樹的缺點
- 壓縮過程有時會幹擾正在進行的讀寫操作
- 日志結構化存儲引擎在更高百分位的響應時間(請參閱“描述性能”)有時會相當長
- B樹的行為則相對更具可預測性
- 在高寫入吞吐量時:硬盤的有限寫入帶寬需要在初始寫入(記錄日志和刷新內存表到硬盤)和在後台運行的壓縮線程之間共享
- 日志結構化存儲引擎在更高百分位的響應時間(請參閱“描述性能”)有時會相當長
- 在B樹索引中,這些鎖可以直接附加到樹上
- B樹的一個優點是每個鍵只存在於索引中的一個位置
- 日志結構化的存儲引擎可能在不同的段中有相同鍵的多個副本
- 壓縮過程有時會幹擾正在進行的讀寫操作
物化視圖
- 一個類似於表的對象,其內容是一些查詢或是aggregate func(sum,min)的結果
- 使得寫入成本更高
- 當底層數據發生變化時,物化視圖需要更新
- 使得寫入成本更高
- 多維度: 數據立方體或OLAP立方
- 一個類似於表的對象,其內容是一些查詢或是aggregate func(sum,min)的結果
事務處理和分析系統
數據倉庫
- 一個獨立的數據庫,分析人員可以查詢他們想要的內容而不影響OLTP操作
- 數據倉庫包含公司各種OLTP系統中所有的只讀數據副本
- 抽取-轉換-加載(ETL)
- 從OLTP數據庫中提取數據(使用定期的數據轉儲或連續的更新流),轉換成適合分析的模式,清理並加載到數據倉庫中。將數據存入倉庫的過程
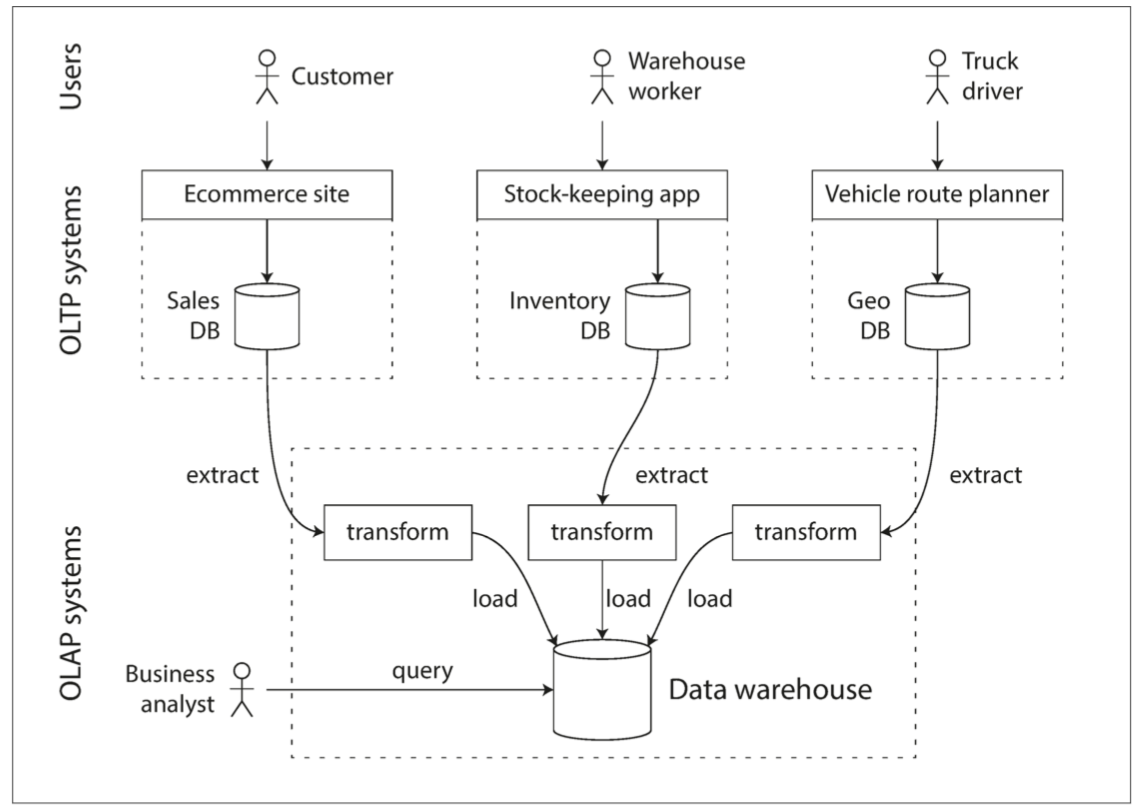
- 分析的模式
- 星型模式
- 在模式的中心是一個所謂的事實表
- 事實表的每一行代表在特定時間發生的事件
- 事實被視為單獨的事件,因為這樣可以在以後分析中獲得最大的靈活性
- 事實表可以變得非常大、寬
- 做列式存儲
- 事實表可以變得非常大、寬
- 事實被視為單獨的事件,因為這樣可以在以後分析中獲得最大的靈活性
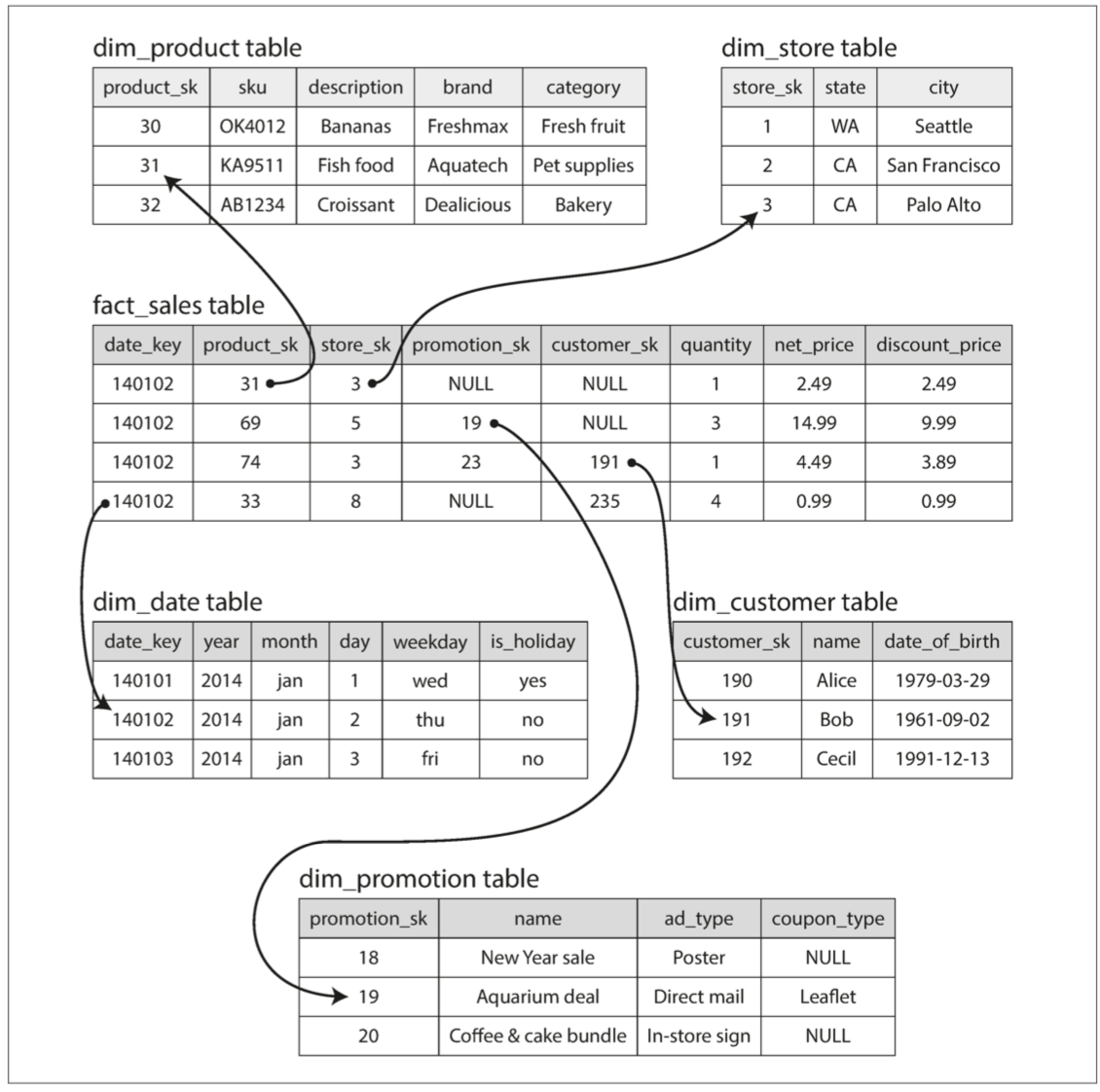
- 事實表的每一行代表在特定時間發生的事件
- 在模式的中心是一個所謂的事實表
- 星型模式
列式存儲
- 方法
- 將來自每一列的所有值存儲在一起
- 每個列式存儲在一個單獨的文件中
- 這樣row的寫入會變得麻煩 => LSM樹
- 所有的寫操作首先進入一個內存中的存儲,在這里它們被添加到一個已排序的結構中,並準備寫入硬盤
- 這樣row的寫入會變得麻煩 => LSM樹
- 好處
- 查詢只需要讀取和解析查詢中使用的那些列
- 這可以節省大量的工作
- 還可以做列壓縮
- 值域通常重複
- 比起用row去讀用col去讀可以用SIMD優化
- 可以對col排序達成類似index與壓縮的效果
- 第一個排序鍵的壓縮效果最強
- 第二和第三個排序鍵會更混亂
- 把用不同col排的資料分散到不同DB!!
- 查詢只需要讀取和解析查詢中使用的那些列
- 方法
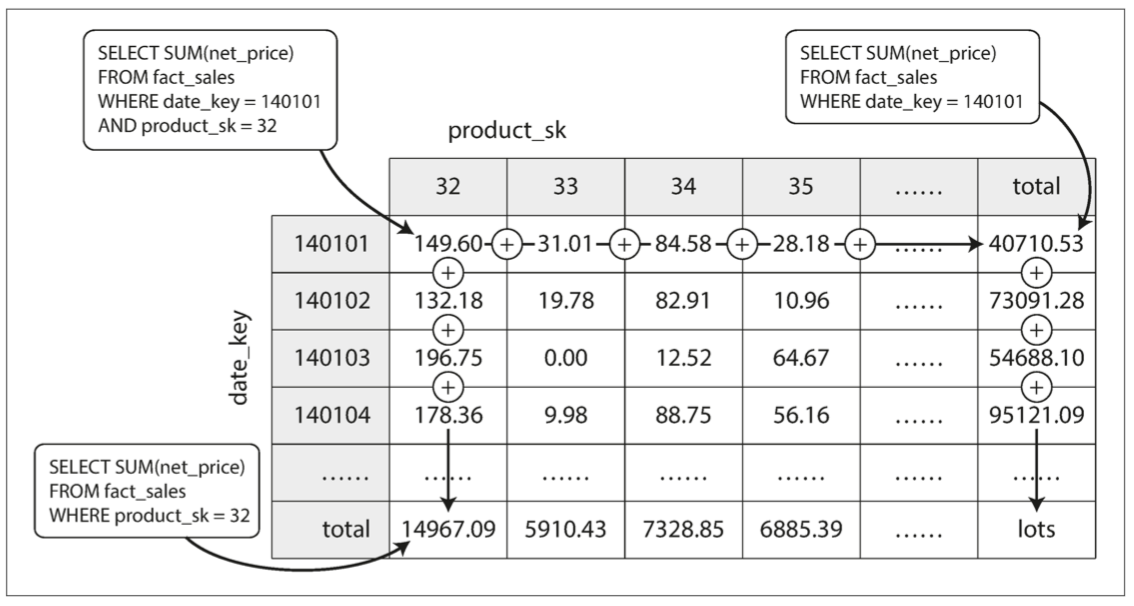

第四章:編碼與演化
可演化性: 有些舊有些新,但都可以動
- 服務端(server-side)
- 滾動升級 (rolling upgrade)
- 客戶端(client-side)
- 升不升級就要看用戶的心情了
雙向兼容性
向後兼容 (backward compatibility)
- 新代碼可以讀舊數據。
- easy
- 新代碼可以讀舊數據。
向前兼容 (forward compatibility)
- 舊代碼可以讀新數據。
- 舊版的程序需要忽略新版數據格式中新增的部分!!
- 舊代碼可以讀新數據。
編碼數據的格式
- 程序通常(至少)使用兩種形式的數據
- 在內存中,數據保存在對象
- 如果要將數據寫入文件,或通過網絡發送,則必須將其 編碼(encode) 為某種自包含的字節序列
- 語言特定的格式
- 這類編碼通常與特定的編程語言深度綁定,其他語言很難讀取這種數據
- 解碼過程需要實例化任意類的能力,這通常是安全問題的一個來源
- 數據版本控制通常是事後才考慮的
- 因為它們旨在快速簡便地對數據進行編碼,所以往往忽略了前向後向兼容性帶來的麻煩問題
- 效率(編碼或解碼所花費的CPU時間,以及編碼結構的大小)往往也是事後才考慮的
- JSON, XML …
- 數值(numbers) 的編碼多有歧義之處
- XML和CSV不能區分數字和字符串
- JSON雖然區分字符串與數值,但不區分整數和浮點數,而且不能指定精度
- JSON和XML對Unicode字符串(即人類可讀的文本)有很好的支持,但是它們不支持二進制數據
- 沒有type做保證 (有也很難用或是沒統一)
- 數值(numbers) 的編碼多有歧義之處
- 二進制編碼
- Thrift與Protocol Buffers
- Thrift和Protocol Buffers每一個都帶有一個代碼生成工具,它采用了類似於這里所示的模式定義,並且生成了以各種編程語言實現模式的類
- 都可以設定
- optional
- args的index
- type
- args的index 與 兼容性
- 編碼的記錄就是其編碼字段的拼接
- 每個字段由其標簽號碼(樣本模式中的數字1,2,3)標識
- 用數據類型(例如字符串或整數)注釋
- 向前兼容性
- 舊的忽略新加的index
- 向後兼容性
- index不變,可以讀舊的
- BUT
- 如果你添加一個新的字段,你不能設置為required
- optional
- 加上預設值
- 如果你添加一個新的字段,你不能設置為required
- 編碼的記錄就是其編碼字段的拼接
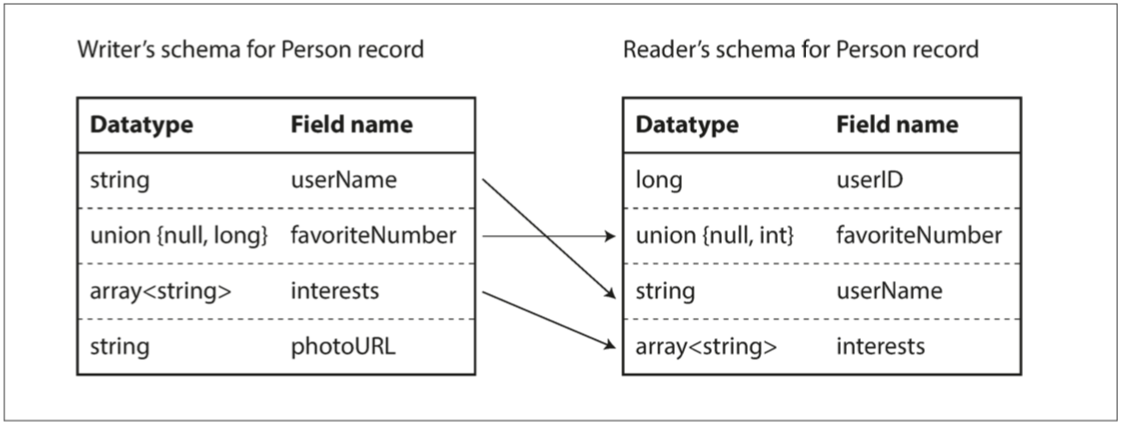
- Avro
- 沒有args的index: 只用名字識別
- 為了解析二進制數據,你按照它們出現在模式中的順序遍歷這些字段,並使用模式來告訴你每個字段的數據類型
- 把解釋的權利交給程式: reader & writer
- 方便動態生成
- 如果數據庫模式發生變化,則可以從更新的數據庫模式生成新的Avro模式,並在新的Avro模式中導出數據。
- 把解釋的權利交給程式: reader & writer
- 為了解析二進制數據,你按照它們出現在模式中的順序遍歷這些字段,並使用模式來告訴你每個字段的數據類型
- Writer模式與Reader模式
- 雖然說分成兩個,其實就是拿一個type去parse看看
- 有對到就ok
- 雖然說分成兩個,其實就是拿一個type去parse看看
- 兼容性
- 只能添加或刪除具有默認值的字段
- 破壞向後兼容性
- 添加一個沒有默認值的字段
- 新的Reader將無法讀取舊Writer寫的數據
- 添加一個沒有默認值的字段
- 破壞向前兼容性
- 刪除沒有默認值的字段
- 舊的Reader將無法讀取新Writer寫入的數據
- 刪除沒有默認值的字段
- 沒有args的index: 只用名字識別
- Thrift與Protocol Buffers
- 語言特定的格式
- 程序通常(至少)使用兩種形式的數據
第五章:覆制
覆制的困難之處在於處理覆制數據的變更(change)
三種流行的變更覆制算法:
- 單領導者(single leader)
- 腳色
- 主庫(master|primary)
- 當客戶端要向數據庫寫入時,它必須將請求發送給領導者,領導者會將新數據寫入其本地存儲
- 追隨者(followers)
- 每當領導者將新數據寫入本地存儲時,它也會將數據變更發送給所有的追隨者,稱之為覆制日志(replication log) 記錄 (change stream)
- 每個跟隨者從領導者拉取日志,並相應更新其本地數據庫副本,方法是按照領導者處理的相同順序應用所有寫入
- 設置新從庫
- 在某個時刻獲取主庫的一致性快照(如果可能),而不必鎖定整個數據庫
- 從庫連接到主庫,並拉取快照之後發生的所有數據變更
- 這要求快照與主庫覆制日志中的位置精確關聯
- 當從庫處理完快照之後積壓的數據變更,我們說它 趕上(caught up) 了主庫
- 主庫(master|primary)
- 同步覆制與異步覆制
- 同步覆制
- 優點
- 從庫保證有與主庫一致的最新數據副本
- 缺點
- 如果同步從庫沒有響應,主庫就無法處理寫入操作
- 主庫必須阻止所有寫入,並等待同步副本再次可用
- 如果同步從庫沒有響應,主庫就無法處理寫入操作
- 所有從庫都設置為同步的是不切實際的
- 在數據庫上啟用同步覆制,通常意味著其中一個跟隨者是同步的
- 這保證你至少在兩個節點上擁有最新的數據副本:主庫和同步從庫
- 這種配置有時也被稱為 半同步(semi-synchronous)
- 優點
- 異步覆制
- 優點
- 即使所有的從庫都落後了,主庫也可以繼續處理寫入
- 缺點
- 如果主庫失效且不可恢覆,則任何尚未覆制給從庫的寫入都會丟失
- 使已經向客戶端確認成功,寫入也不能保證 持久(Durable
- 如果主庫失效且不可恢覆,則任何尚未覆制給從庫的寫入都會丟失
- 優點
- 同步覆制
- 處理節點宕機
- 從庫失效:追趕恢覆
- 主庫失效:故障切換
- steps
- 確認主庫失效
- 大多數系統只是簡單使用 超時(Timeout)
- 節點頻繁地相互來回傳遞消息,並且如果一個節點在一段時間內沒有響應,就認為它掛了
- 大多數系統只是簡單使用 超時(Timeout)
- 選擇一個新的主庫
- 可以通過選舉過程(主庫由剩余副本以多數選舉產生)來完成
- 可以由之前選定的控制器節點(controller node) 來指定新的主庫
- 重新配置系統以啟用新的主庫。客戶端現在需要將它們的寫請求發送給新主庫
- 系統需要確保舊主庫意識到新主庫的存在,並成為一個從庫
- 確認主庫失效
- 要注意的
- 如果使用異步覆制,則新主庫可能沒有收到老主庫宕機前最後的寫入操作
- 如果老主庫重新加入集群,新主庫在此期間可能會收到沖突的寫入,那這些寫入該如何處理?
- 如果數據庫需要和其他外部存儲相協調,那麽丟棄寫入內容是極其危險的操作
- github的redis與DB (數據庫使用自增ID作為主鍵)
- 可能會出現兩個節點都以為自己是主庫的情況
- 主庫被宣告死亡之前的正確超時應該怎麽配置? (timeout要剛好!!)
- steps
- 覆制日志的實現
- 基於語句的覆制
- 主庫記錄下它執行的每個寫入請求(語句,即statement)並將該語句日志發送給其從庫
- 問題是
- 非確定性函數(nondeterministic)
- 自增列(auto increment)
- 有副作用的語句
- 傳輸預寫式日志(WAL)
- 日志都是包含所有數據庫寫入的僅追加字節序列
- 可以使用完全相同的日志在另一個節點上構建副本
- 問題是
- 日志記錄的數據非常底層
- WAL包含哪些磁盤塊中的哪些字節發生了更改
- 這使覆制與存儲引擎緊密耦合
- 如果要升級DB的話…
- 日志記錄的數據非常底層
- 日志都是包含所有數據庫寫入的僅追加字節序列
- 邏輯日志覆制(基於行)
- 覆制和存儲引擎使用不同的日志格式,這樣可以使覆制日志從存儲引擎內部分離出來
- 對於插入的行,日志包含所有列的新值。
- 對於刪除的行,日志包含足夠的信息來唯一標識已刪除的行
- 對於更新的行,日志包含足夠的信息來唯一標識更新的行
- 這樣就可以把DB變動當成資料流!!
- 覆制和存儲引擎使用不同的日志格式,這樣可以使覆制日志從存儲引擎內部分離出來
- 基於語句的覆制
- 覆制延遲問題
- 當應用程序從異步從庫讀取時,如果從庫落後,它可能會看到過時的信息
- 複製的一致性的種種問題
- 讀己之寫: 讀寫一致性(read-after-write consistency)
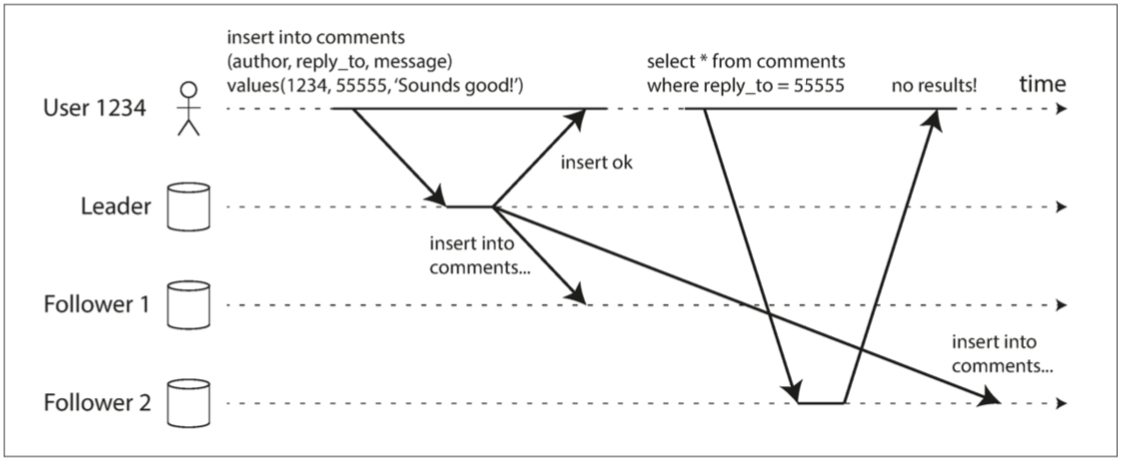
- 解
- 都從主庫讀
- 讀用戶可能已經修改過的內容時
- 使用其他標準來決定是否從主庫讀取
- 客戶端可以記住最近一次寫入的時間戳
- 系統需要確保從庫為該用戶提供任何查詢時,該時間戳前的變更都已經傳播到了本從庫中
- 都從主庫讀
- 跨設備的寫後讀一致性
- 記住用戶上次更新時間戳的方法變得更加困難
- 元數據需要一個中心存儲
- 如果副本分布在不同的數據中心,很難保證來自不同設備的連接會路由到同一數據中心
- 4G與wifi
- 記住用戶上次更新時間戳的方法變得更加困難
- 單調讀(Monotonic reads
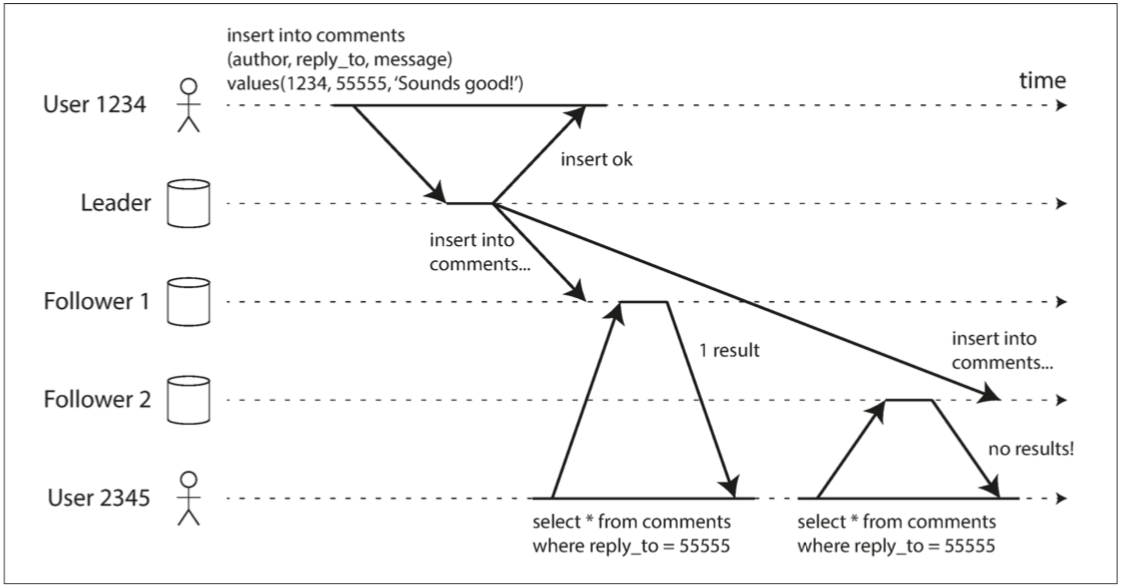
- 如果先前讀取到較新的數據,後續讀取不會得到更舊的數據
- 解
- 實現單調讀取的一種方式是確保每個用戶總是從同一個副本進行讀取
- 可以基於用戶ID的散列來選擇副本
- 實現單調讀取的一種方式是確保每個用戶總是從同一個副本進行讀取
- 一致前綴讀(consistent prefix reads)
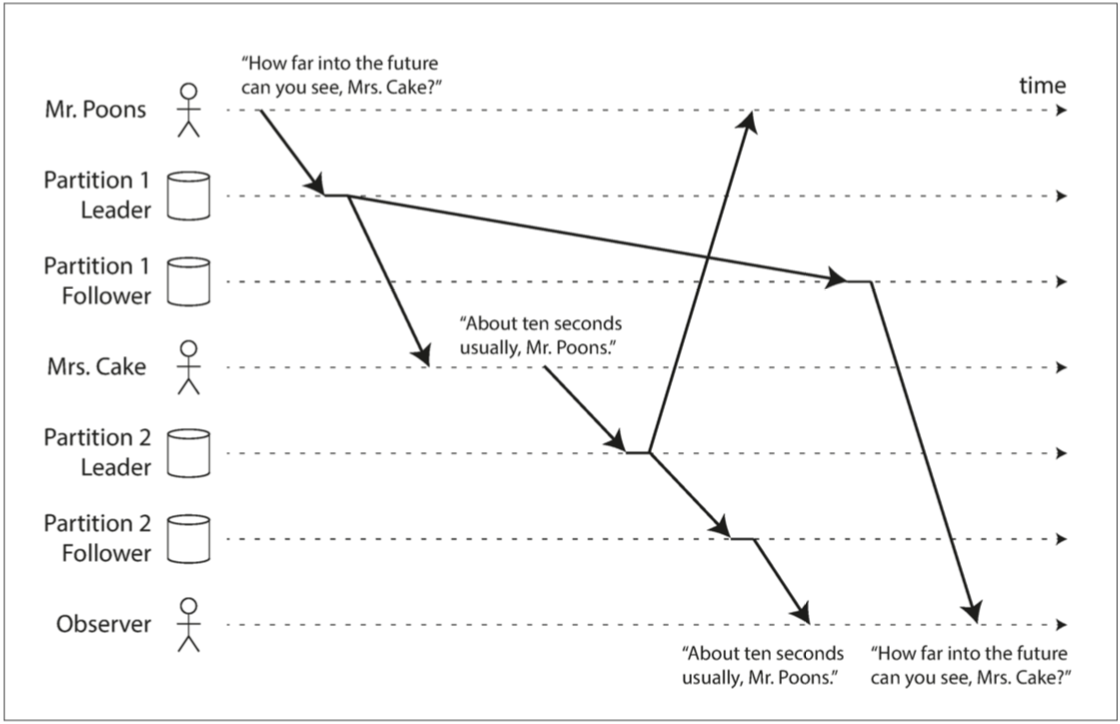
- 如果一系列寫入按某個順序發生,那麽任何人讀取這些寫入時,也會看見它們以同樣的順序出現
- 不存在全局寫入順序!!
- 如果一系列寫入按某個順序發生,那麽任何人讀取這些寫入時,也會看見它們以同樣的順序出現
- 解
- 確保任何因果相關的寫入都寫入相同的分區
- 讀己之寫: 讀寫一致性(read-after-write consistency)
- 腳色
- 多領導者(multi leader)
- 允許多個節點接受寫入
- 覆制仍然以同樣的方式發生:處理寫入的每個節點都必須將該數據更改轉發給所有其他節點
- scenario
- 副本分散在好幾個不同的數據中心
- 兩個不同的數據中心可能會同時修改相同的數據,寫沖突是必須解決的
- 需要離線操作的客戶端
- 應用程序在斷網之後仍然需要繼續工作
- 協同編輯
- 副本分散在好幾個不同的數據中心
- 處理寫入沖突
- 同步與異步沖突檢測
- 使沖突檢測同步 - 即等待寫入被覆制到所有副本,然後再告訴用戶寫入成功
- 失去多主覆制的主要優點:允許每個副本獨立接受寫入
- 使沖突檢測同步 - 即等待寫入被覆制到所有副本,然後再告訴用戶寫入成功
- 收斂至一致的狀態
- 在多主配置中,沒有明確的寫入順序,所以最終值應該是什麽並不清楚
- 給每個寫入一個唯一的ID,挑選最高ID的寫入作為勝利者 (LWW, last write wins)
- 以某種方式將這些值合並在一起 - 例如,按字母順序排序,然後連接它們
- 用一種可保留所有信息的顯式數據結構來記錄沖突,並編寫解決沖突的應用程序代碼
- 在多主配置中,沒有明確的寫入順序,所以最終值應該是什麽並不清楚
- 避免沖突
- 確保來自特定用戶的請求始終路由到同一數據中心,並使用該數據中心的領導者進行讀寫
- 但是,有時你可能需要更改指定的記錄的主庫
- 還是必須處理不同主庫同時寫入的可能性
- 但是,有時你可能需要更改指定的記錄的主庫
- 確保來自特定用戶的請求始終路由到同一數據中心,並使用該數據中心的領導者進行讀寫
- 自定義沖突解決邏輯
- 寫時執行
- 只要數據庫系統檢測到覆制更改日志中存在沖突,就會調用沖突處理程序
- 讀時執行
- 當檢測到沖突時,所有沖突寫入被存儲
- 下一次讀取數據時,會將這些多個版本的數據返回給應用程序。
- 應用程序可能會提示用戶或自動解決沖突
- 當檢測到沖突時,所有沖突寫入被存儲
- 寫時執行
- 多主覆制拓撲
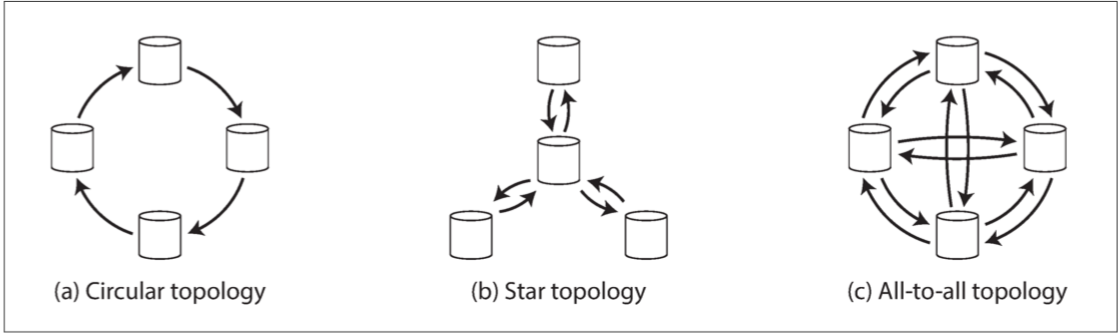
- 環形和星形拓撲的問題
- 如果只有一個節點發生故障,則可能會中斷其他節點之間的覆制消息流
- 全部到全部拓撲的問題
- 一些網絡鏈接可能比其他網絡鏈接更快,結果是一些覆制消息可能“超過”其他覆制消息
- 解
- 用版本向量 (vector time)
- 解
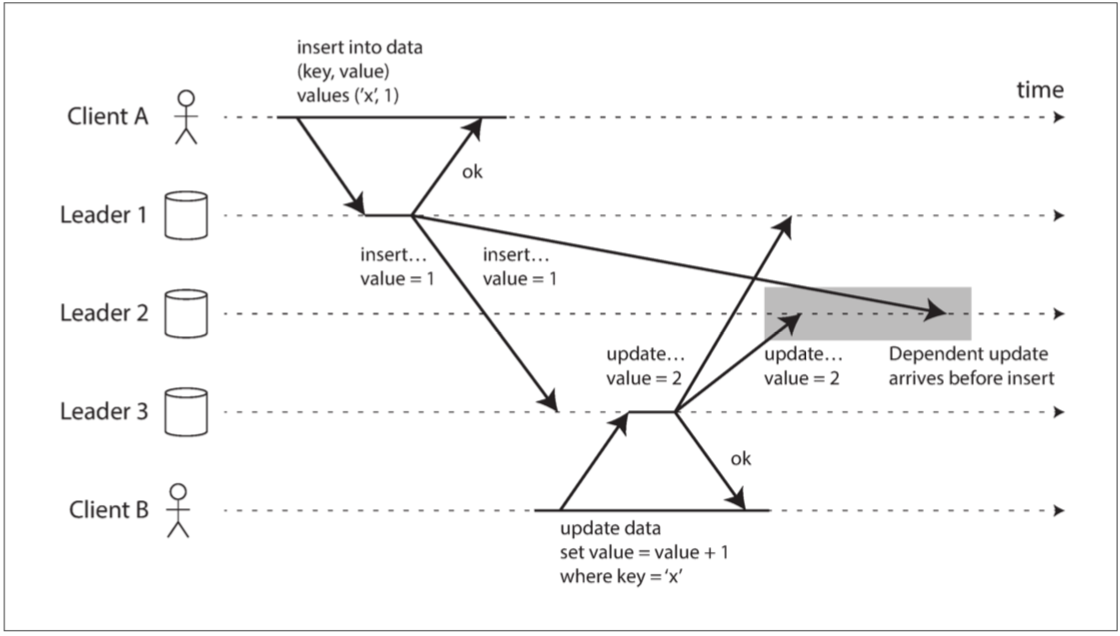
- 一些網絡鏈接可能比其他網絡鏈接更快,結果是一些覆制消息可能“超過”其他覆制消息
- 環形和星形拓撲的問題
- 同步與異步沖突檢測
- 允許多個節點接受寫入
- 無領導者(leaderless)
- 放棄主庫的概念,並允許任何副本直接接受來自客戶端的寫入
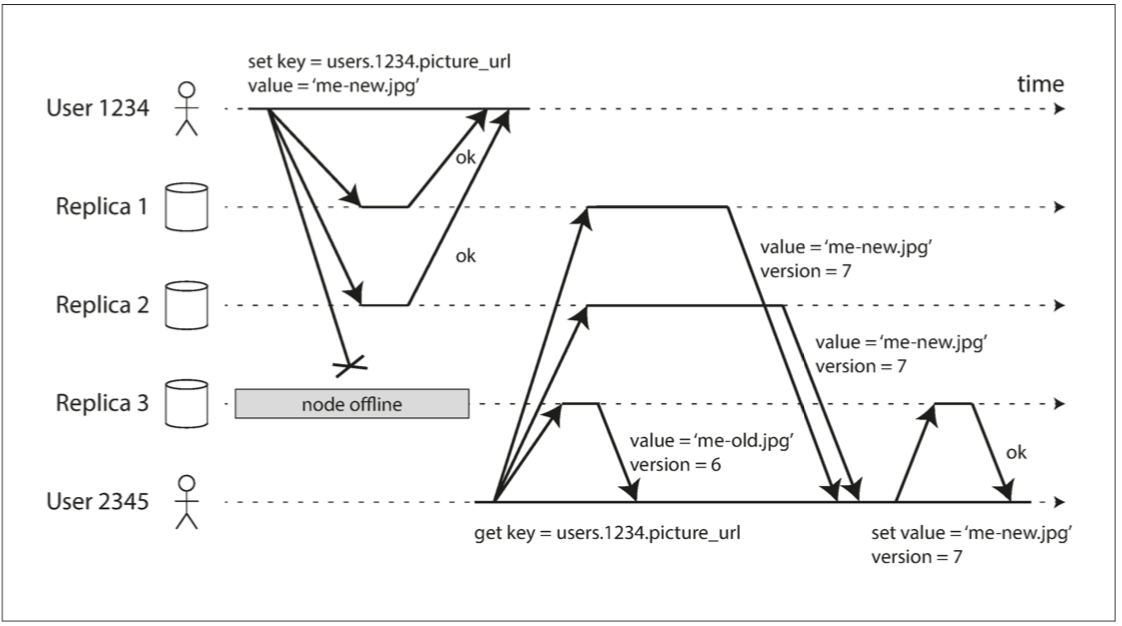
- 過法定人數就算成功
- 只要w + r> n,我們期望在讀取時獲得最新的值
- 因為r個讀取中至少有一個節點是最新的
- 遵循這些r值,w值的讀寫稱為法定人數(quorum)的讀和寫
- 重要的前提
- 寫入的節點集合和你讀取的節點集合必須重疊
- 你讀取的節點中必須至少有一個具有最新值的節點
- 寫入的節點集合和你讀取的節點集合必須重疊
- 法定人數一致性的局限性
- 即使在w + r> n的情況下,也可能存在返回陳舊值的邊緣情況
- 例子
- 如果使用寬松的法定人數,w個寫入和r個讀取落在完全不同的節點上
- 寬松的法定人數
- 網絡中斷期間客戶端可能仍能連接到一些數據庫節點,但又不足以組成一個特定值的法定人數
- 這時可以
- 返回錯誤
- 接受寫入,然後將它們寫入一些其他可達的節點,但不在這些值通常所存在的n個節點上 (寬松的法定人數)
- 然而,這意味著即使當w + r> n時,也不能確定讀取某個鍵的最新值,因為最新的值可能已經臨時寫入了n之外的某些節點
- 這時可以
- 網絡中斷期間客戶端可能仍能連接到一些數據庫節點,但又不足以組成一個特定值的法定人數
- 寬松的法定人數
- 如果兩個寫入同時發生,不清楚哪一個先發生
- 如果寫操作與讀操作同時發生,寫操作可能僅反映在某些副本上
- 不確定讀取是返回舊值還是新值
- 如果寫操作在某些副本上成功,而在其他節點上失敗 (對面HDD爆了)
- 所以整體判定寫入失敗,但整體寫入失敗並沒有在寫入成功的副本上回滾
- 後續的讀取仍然可能會讀取這次失敗寫入的值
- 即使一切工作正常,有時也會不幸地出現關於時序(timing) 的邊緣情況
- 如果使用寬松的法定人數,w個寫入和r個讀取落在完全不同的節點上
- 例子
- 即使在w + r> n的情況下,也可能存在返回陳舊值的邊緣情況
- 只要w + r> n,我們期望在讀取時獲得最新的值
- 過法定人數就算成功
- 即使應用可以容忍陳舊的讀取,你也需要了解覆制的健康狀況
- 如果顯著落後,應該提醒你,以便你可以調查原因
- 在一個不可用的節點重新聯機之後,它如何趕上它錯過的寫入
- 讀修覆(Read repair)
- 當客戶端並行讀取多個節點時,它可以檢測到任何陳舊的響應,並將新值寫回到該副本
- 反熵過程(Anti-entropy process)
- 後台進程,該進程不斷查找副本之間的數據差異,並將任何缺少的數據從一個副本覆制到另一個副本
- 讀修覆(Read repair)
- 檢測並發寫入
- 問題在於,由於可變的網絡延遲和部分故障,事件可能在不同的節點以不同的順序到達
- 手法 (與多領導者的很像)
- 最後寫入勝利(丟棄並發寫入)
- “此前發生”的關系和並發
- timestamp (安全令牌, lamport time)
- 服務器為每個鍵保留一個版本號,每次寫入鍵時都增加版本號,並將新版本號與寫入的值一起存儲。
- 當客戶端讀取鍵時,服務器將返回所有未覆蓋的值以及最新的版本號。客戶端在寫入前必須讀取。
- 客戶端寫入鍵時,必須包含之前讀取的版本號,並且必須將之前讀取的所有值合並在一起
- 當服務器接收到具有特定版本號的寫入時,它可以覆蓋該版本號或更低版本的所有值
- timestamp (安全令牌, lamport time)
- 合並同時寫入的值
- 一個簡單的方法是根據版本號或時間戳做union
- 不能處理直接刪除的case (
{1} | {x1x, 2} = {1, 2})- 墓碑(tombstone, soft delete)
- 不能處理直接刪除的case (
- 一個簡單的方法是根據版本號或時間戳做union
- 版本向量 (vector time)
- 副本在處理寫入時增加自己的版本號,並且跟蹤從其他副本中看到的版本號
- 這個信息指出了要覆蓋哪些並發值,以及保留哪些並發值。
第六章:分區
分區通常與覆制結合使用,使得每個分區的副本存儲在多個節點上
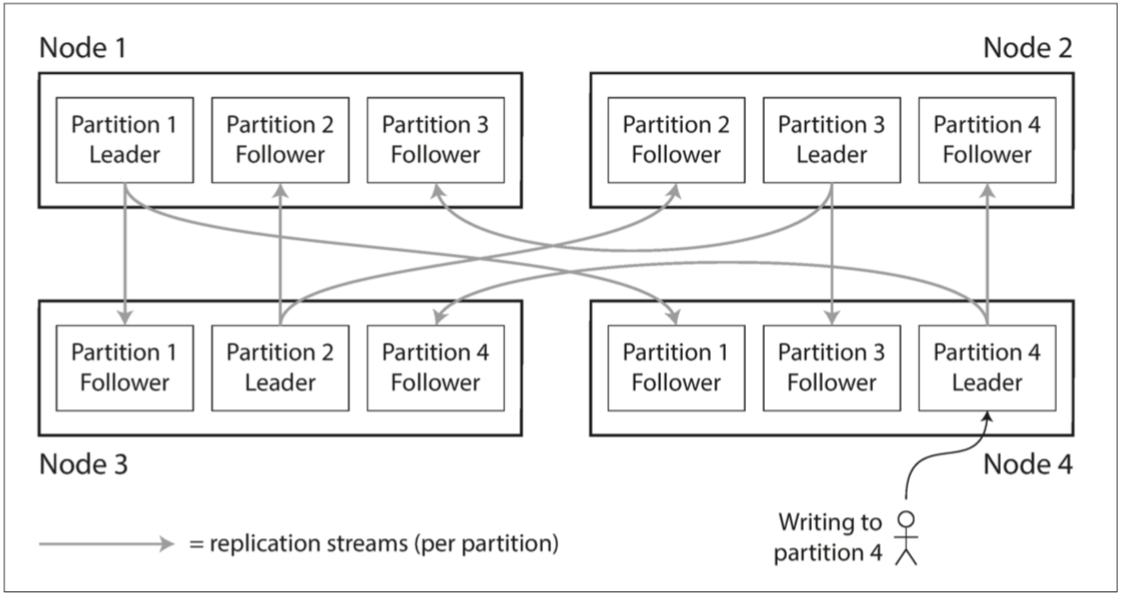
- 怎麼分配key
- 一些分區比其他分區有更多的數據或查詢,我們稱之為偏斜(skew)
- 不均衡導致的高負載的分區被稱為熱點(hot spot)
- 作法
- 將記錄隨機分配給節點
- 當你試圖讀取一個特定的值時,你無法知道它在哪個節點上
- 必須並行地查詢所有的節點
- 當你試圖讀取一個特定的值時,你無法知道它在哪個節點上
- 為每個分區指定一塊連續的鍵範圍(從最小值到最大值)
- 鍵的範圍不一定均勻分布,因為數據也很可能不均勻分布
- 分區邊界可以由管理員手動選擇,也可以由數據庫自動選擇 (分區再平衡)
- Key Range分區的缺點是某些特定的訪問模式會導致熱點
- 如果主鍵是時間戳,則分區對應於時間範圍
- 今天會先被塞爆
- 需要使用除了時間戳以外的其他東西作為主鍵的第一個部分
- 今天會先被塞爆
- 如果主鍵是時間戳,則分區對應於時間範圍
- 鍵的範圍不一定均勻分布,因為數據也很可能不均勻分布
- hash function
- 一致性哈希,即consistent hashing
- 失去高效執行範圍查詢的能力
- 將記錄隨機分配給節點
- 負載偏斜與熱點消除
- 這個key就是熱門 (藝人)
- 所有的請求都會被路由到同一個分區
- 一個簡單的方法是在主鍵的開始或結尾添加一個隨機數
- 將主鍵進行分割之後,任何讀取都必須要做額外的工作,因為他們必須從所有主鍵分布中讀取數據並將其合並
- 這個key就是熱門 (藝人)
- 分區與次級索引
- 次級索引的問題是它們不能整齊地映射到分區
- 次級索引通常並不能唯一地標識記錄,而是一種搜索記錄中出現特定值的方式
- 查找包含詞語hogwash的所有文章,查找所有顏色為紅色的車輛等等
- 次級索引通常並不能唯一地標識記錄,而是一種搜索記錄中出現特定值的方式
- 兩種作法
- 基於文檔
- 在這種索引方法中,每個分區是完全獨立的
- 每個分區維護自己的次級索引,僅覆蓋該分區中的文檔
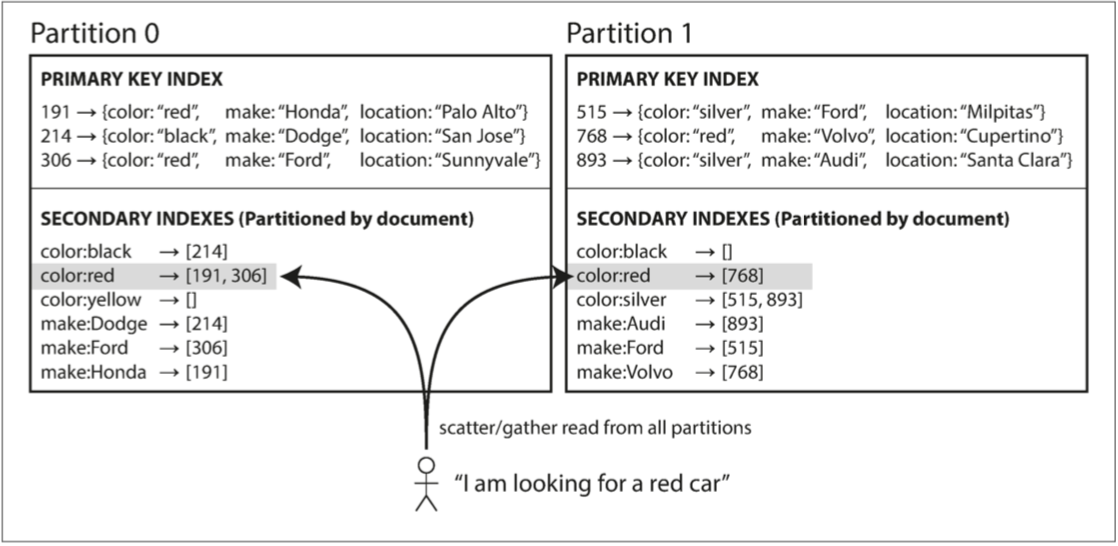
- 缺點
- 可能會使次級索引上的讀取查詢相當昂貴 *
- 在這種索引方法中,每個分區是完全獨立的
- 基於關鍵詞(Term)
- 一個覆蓋所有分區數據的全局索引,而不是給每個分區創建自己的次級索引(本地索引)
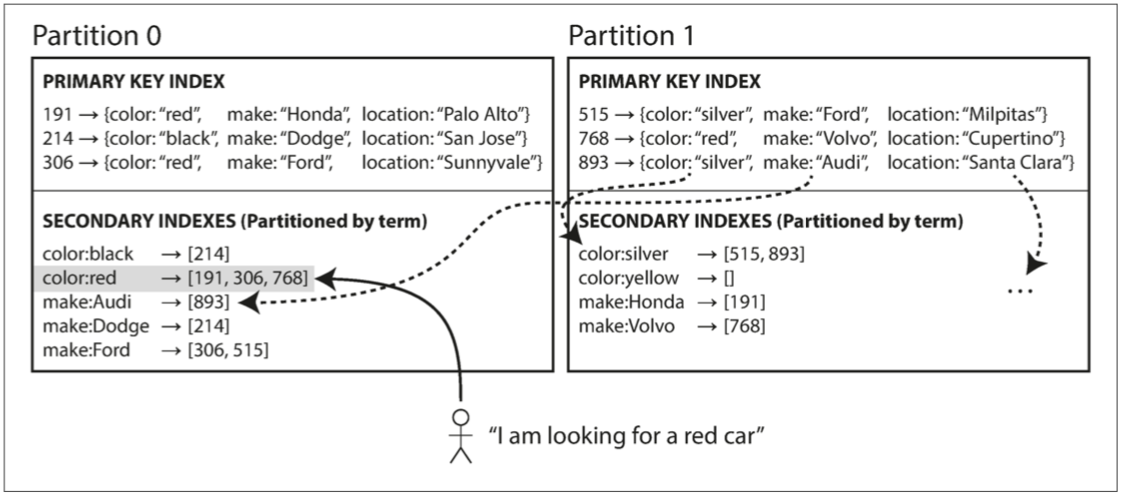
- 缺點
- 寫入速度較慢且較為覆雜,因為寫入單個文檔現在可能會影響索引的多個分區
- 基於文檔
- 次級索引的問題是它們不能整齊地映射到分區
- 分區再平衡
- 將負載從集群中的一個節點向另一個節點移動的過程稱為再平衡(rebalancing)
- 要求
- 再平衡之後,負載(數據存儲,讀取和寫入請求)應該在集群中的節點之間公平地共享。
- 再平衡發生時,數據庫應該繼續接受讀取和寫入。
- 節點之間只移動必須的數據,以便快速再平衡,並減少網絡和磁盤I/O負載。
- 方法
- 反面教材:hash mod N
- 如果節點數量N發生變化,大多數鍵將需要從一個節點移動到另一個節點
- 固定數量的分區
- 創建比節點更多的分區,並為每個節點分配多個分區
- 如果一個節點被添加到集群中,新節點可以從當前每個節點中竊取一些分區,直到分區再次公平分配
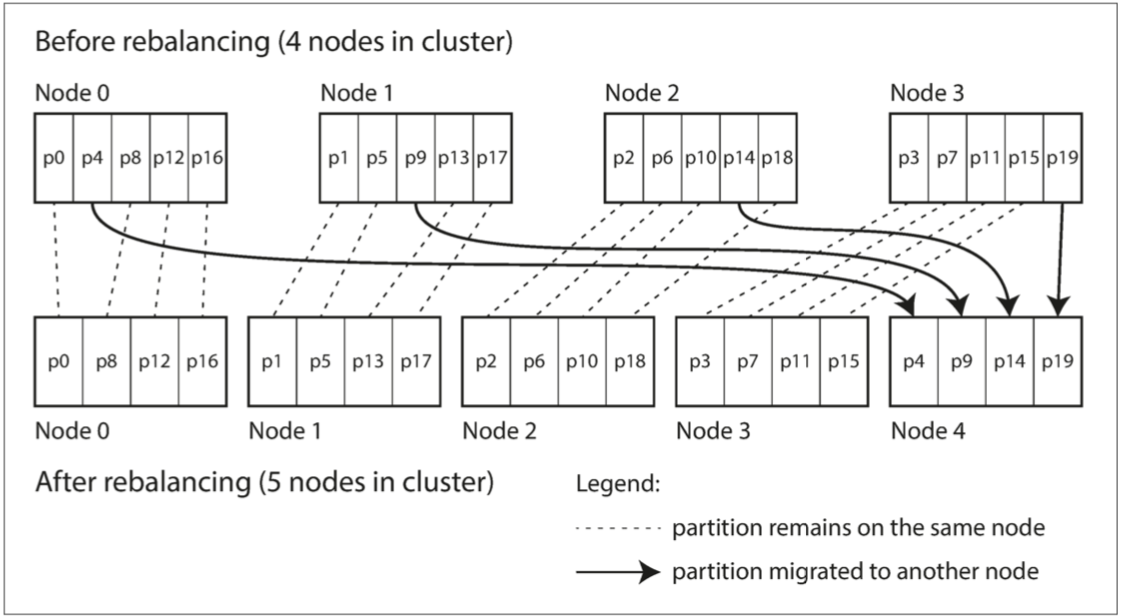
- 創建比節點更多的分區,並為每個節點分配多個分區
- 固定總大小的動態分區
- 按鍵的範圍進行分區的數據庫會動態創建分區
- 當分區增長到超過配置的大小時,會被分成兩個分區,每個分區約占一半的數據
- 此過程與B樹頂層發生的過程類似
- 動態分區的一個優點是分區數量適應總數據量
- 一個空的數據庫從一個分區開始,因為沒有關於在哪里繪制分區邊界的先驗信息
- 數據集開始時很小,直到達到第一個分區的分割點,所有寫入操作都必須由單個節點處理
- 按鍵的範圍進行分區的數據庫會動態創建分區
- 固定節點上分區數量的分區
- 使分區數與節點數成正比
- 當一個新節點加入集群時,它隨機選擇固定數量的現有分區進行拆分,然後占有這些拆分分區中每個分區的一半,同時將每個分區的另一半留在原地
- 隨機化可能會產生不公平的分割
- 反面教材:hash mod N
- 運維:手動還是自動再平衡
- 再平衡的過程中有人參與是一件好事
- 這種自動化與自動故障檢測相結合可能十分危險
- 假設一個節點過載,並且對請求的響應暫時很慢
- 其他節點得出結論:過載的節點已經死亡,並自動重新平衡集群,使負載離開它
- 這會對已經超負荷的節點,其他節點和網絡造成額外的負載
- 這種自動化與自動故障檢測相結合可能十分危險
- 再平衡的過程中有人參與是一件好事
- 請求路由
- 我要怎麼知道找誰
- 作出路由決策的組件(可能是節點之一,還是路由層或客戶端)如何了解分區-節點之間的分配關系變化?
- 因為重要的是所有參與者都達成共識 - 否則請求將被發送到錯誤的節點
- 作出路由決策的組件(可能是節點之一,還是路由層或客戶端)如何了解分區-節點之間的分配關系變化?
- 不同的方案
- 允許客戶聯系任何節點
- 請求發送到路由層,它決定了應該處理請求的節點,並相應地轉發
- 要求客戶端知道分區和節點的分配
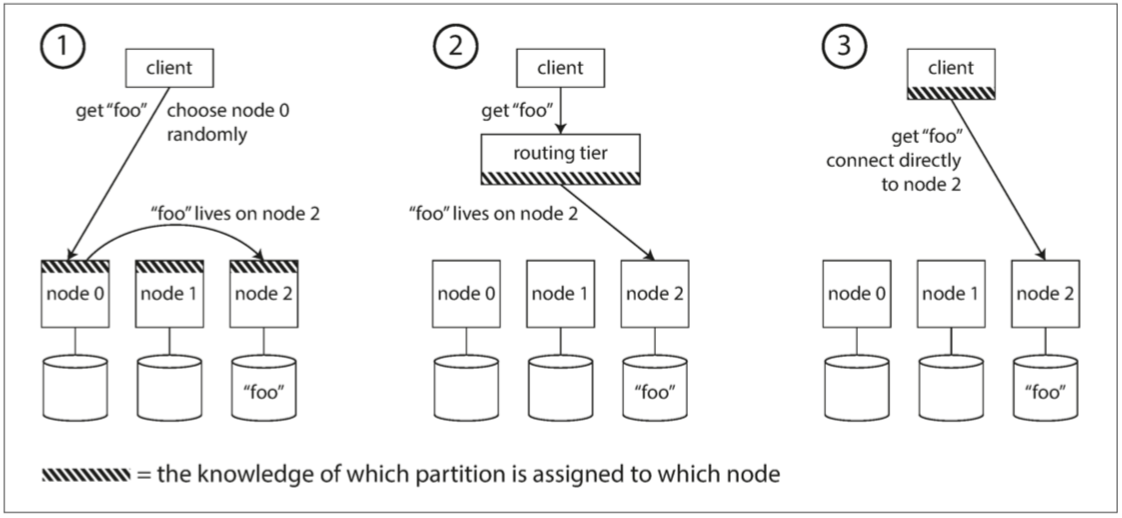
- 我要怎麼知道找誰
第七章:事務
- 隔離級別
- 讀已提交(Read Committed)
- 從數據庫讀時,只能看到已提交的數據(沒有臟讀,即dirty reads)。
- 寫入數據庫時,只會覆蓋已經寫入的數據(沒有臟寫,即dirty writes)。
- 最常見的情況是,數據庫通過使用行鎖(row-level lock) 來防止臟寫
- 因為等待鎖,應用某個部分的遲緩可能由於連鎖效應,導致其他部分出現問題
- 解
- 對於寫入的每個對象,數據庫都會記住舊的已提交值,和由當前持有寫入鎖的事務設置的新值
- 當事務正在進行時,任何其他讀取對象的事務都會拿到舊值
- 只有當新值提交後,事務才會切換到讀取新值。
- 解
- 因為等待鎖,應用某個部分的遲緩可能由於連鎖效應,導致其他部分出現問題
- 可重覆讀
- 中間遇到commit的值,讓read不一樣
- 有些情況下,不能容忍這種暫時的不一致
- 備份
- 分析查詢和完整性檢查
- 解
- 快照隔離
- 每個事務都從數據庫的一致快照(consistent snapshot) 中讀取
- 事務可以看到事務開始時在數據庫中提交的所有數據。
- 即使這些數據隨後被另一個事務更改,每個事務也只能看到該特定時間點的舊數據
- 每個事務都從數據庫的一致快照(consistent snapshot) 中讀取
- 實現快照隔離
- 通常使用寫鎖來防止臟寫,這意味著進行寫入的事務會阻止另一個事務修改同一個對象 &
- 快照隔離的一個關鍵原則是:讀不阻塞寫,寫不阻塞讀
- 數據庫必須可能保留一個對象的幾個不同的提交版本 (mvcc)
- 因為各種正在進行的事務可能需要看到數據庫在不同的時間點的狀態
- 通常使用寫鎖來防止臟寫,這意味著進行寫入的事務會阻止另一個事務修改同一個對象 &
- 一致性快照的可見性規則
- 條件
- 讀事務開始時,創建該對象的事務已經提交。
- 對象未被標記為刪除,或如果被標記為刪除,請求刪除的事務在讀事務開始時尚未提交。
- steps
- 在每次事務開始時,數據庫列出當時所有其他(尚未提交或尚未中止)的事務清單,即使之後提交了,這些事務已執行的任何寫入也都會被忽略。
- 被中止事務所執行的任何寫入都將被忽略。
- 由具有較晚事務ID(即,在當前事務開始之後開始的)的事務所做的任何寫入都被忽略,而不管這些事務是否已經提交。
- 所有其他寫入,對應用都是可見的。
- 條件
- 快照隔離
- 丟失更新 (老朋友)
- 只有一個副本
- 原子寫
- 顯式鎖定
- 比較並設置(CAS)
- 多主或無主覆制
- 沖突解決和覆制 (看前面)
- 只有一個副本
- 寫入偏斜與幻讀
- 寫偏差
- 更新不同row (row能鎖,但在此不用鎖)
- 依據某個exclusive的條件,兩者同時更新 (這個沒辦法鎖)
- Alice和Bob是兩位值班醫生。兩人都感到不適,所以他們都決定請假
- 不幸的是,他們恰好在同一時間點擊按鈕下班
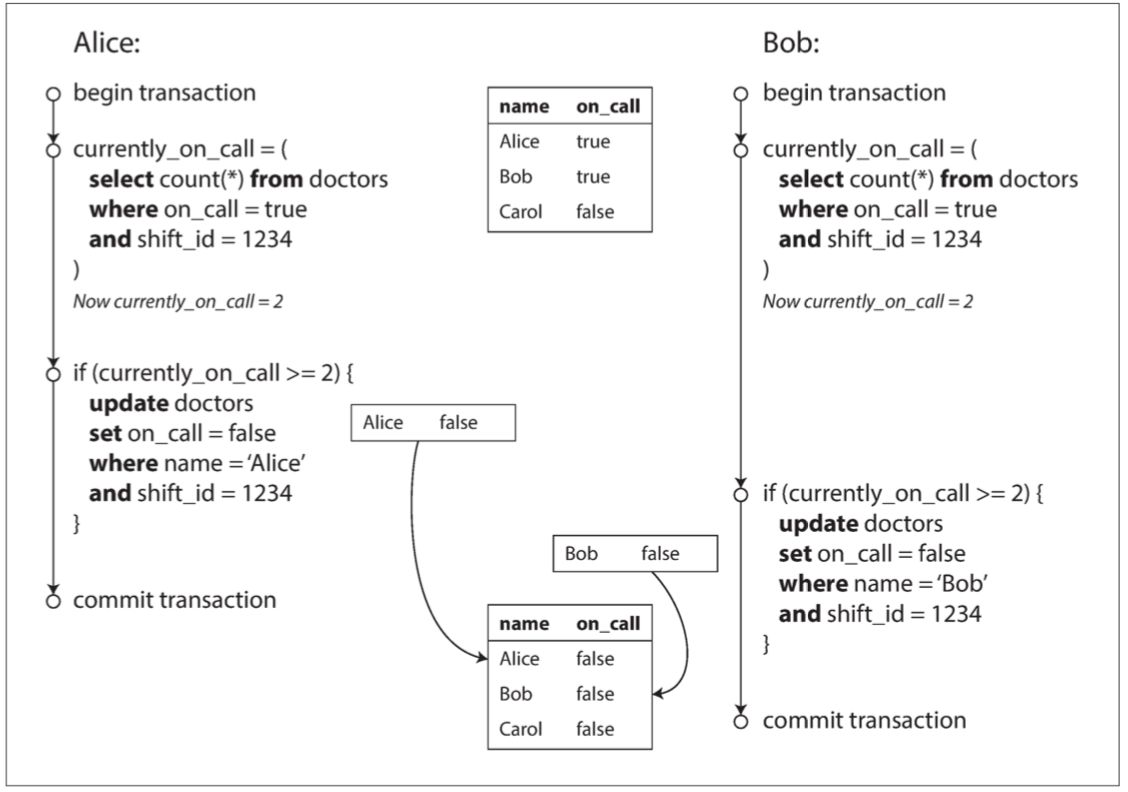
- 導致寫入偏差的幻讀 的 pattern
- 一個SELECT查詢找出符合條件的行,並檢查是否符合一些要求
- 按照第一個查詢的結果,應用代碼決定是否繼續
- 如果應用決定繼續操作,就執行寫入(插入、更新或刪除),並提交事務
- 解
- 物化沖突(materializing conflicts)
- 弄清楚如何物化沖突可能很難,也很容易出錯
- 並發控制機制泄漏到應用數據模型是很醜陋的做法
- 可串行化(Serializable)
- 真的串行執行
- 在單個線程上按順序一次只執行一個事務
- 單線程循環執行事務是可行的!!
- RAM足夠便宜了,許多場景現在都可以將完整的活躍數據集保存在內存中
- 數據庫設計人員意識到OLTP事務通常很短,而且只進行少量的讀寫操作
- 其吞吐量僅限於單個CPU核的吞吐量
- 為了充分利用單一線程,需要與傳統形式的事務不同的結構
- 在這種交互式的事務方式中,應用程序和數據庫之間的網絡通信耗費了大量的時間
- 如果不允許在數據庫中進行並發處理,且一次只處理一個事務,則吞吐量將會非常糟糕
- SO, 具有單線程串行事務處理的系統不允許交互式的多語句事務
- 取而代之,應用程序必須提前將整個事務代碼作為存儲過程提交給數據庫
- 存儲過程
- 優點
- 存儲過程與內存存儲,使得在單個線程上執行所有事務變得可行
- 不需要等待I/O
- 避免了並發控制機制的開銷
- 單個線程上實現相當好的吞吐量
- 不需要等待I/O
- 存儲過程與內存存儲,使得在單個線程上執行所有事務變得可行
- 缺點
- 每個數據庫廠商都有自己的存儲過程語言
- 在數據庫中運行的代碼難以管理
- 數據庫通常比應用服務器對性能敏感的多,因為單個數據庫實例通常由許多應用服務器共享
- 寫不好大家出事
- 優點
- 存儲過程
- 取而代之,應用程序必須提前將整個事務代碼作為存儲過程提交給數據庫
- 單線程循環執行事務是可行的!!
- 在單個線程上按順序一次只執行一個事務
- 兩階段鎖定(2PL,two-phase locking)
- 在2PL中,寫入不僅會阻塞其他寫入,也會阻塞讀,反之亦然
- 快照隔離使得讀不阻塞寫,寫也不阻塞讀
- 一次拿所有的鎖,跑,一次放掉
- 缺點
- 如果transcation跑很久
- 整個效能就很慢 (高百分位點處的響應會非常的慢)
- 可能發生死鎖
- 但在基於2PL實現的可串行化隔離級別中,它們會出現的頻繁的多
- 如果transcation跑很久
- 謂詞鎖
- 條件可以上鎖!!
- 有range版
- 在2PL中,寫入不僅會阻塞其他寫入,也會阻塞讀,反之亦然
- 可串行化快照隔離(SSI, serializable snapshot isolation)
- 數據庫如何知道查詢結果是否可能已經改變? (前提變了)
- 檢測舊MVCC讀取
- 數據庫需要跟蹤一個事務由於MVCC可見性規則而忽略另一個事務的寫入
- 當事務想要提交時,數據庫檢查是否有任何被忽略的寫入現在已經被提交
- 如果是這樣,事務必須中止
- 檢測影響之前讀取的寫入
- SSI鎖類似謂詞鎖,但不會阻塞其他事務 (一個記號)
- 提交時,若其他事務的沖突寫入已經被提交(有記號)
- 事務必須中止
- 檢測舊MVCC讀取
- 優點
- 事務不需要阻塞等待另一個事務所持有的鎖
- 不局限於單個CPU核的吞吐量
- 缺點
- 長時間讀取和寫入數據的事務很可能會發生沖突並中止
- 因此SSI要求同時讀寫的事務盡量短
- 長時間讀取和寫入數據的事務很可能會發生沖突並中止
- 數據庫如何知道查詢結果是否可能已經改變? (前提變了)
- 真的串行執行
- 物化沖突(materializing conflicts)
- 寫偏差
- 讀已提交(Read Committed)
第八章:分布式系統的麻煩
使用分布式系統與在一台計算機上編寫軟件有著根本的區別,主要的區別在於有許多新穎和刺激的方法可以使事情出錯
去理解我們能夠依賴,和不可以依賴的東西
沒有共享內存,只有通過可變延遲的不可靠網絡傳遞的消息,系統可能遭受部分失效,不可靠的時鐘和處理暫停
網絡中的一個節點無法確切地知道任何事情——它只能根據它通過網絡接收到(或沒有接收到)的消息進行猜測。
不能確定對面是不是在搞 (拜占庭問題)
在分布式系統中,我們可以陳述關於行為(系統模型)的假設,並以滿足這些假設的方式設計實際系統。算法可以被證明在某個系統模型中正確運行。這意味著即使底層系統模型提供了很少的保證,也可以實現可靠的行為
- 部分失效
- 在一台電腦上
- 如果發生內部錯誤,我們寧願電腦完全崩潰,而不是返回錯誤的結果,因為錯誤的結果很難處理
- 在分布式系統
- 只能面對現實世界的混亂現實,容忍錯誤
- 部分失效(partial failure)
- 盡管系統的其他部分工作正常,但系統的某些部分可能會以某種不可預知的方式被破壞
- 部分失效是不確定性的(nonderterministic)
- 在一台電腦上
- 不可靠的網絡
- 發送請求並期待響應,則很多事情可能會出錯 (不會知道對面發生什麼事導致lost)
- 請求可能已經丟失
- 請求可能正在排隊,稍後將交付
- 遠程節點可能已經失效
- 遠程節點可能暫時停止了響應 (進程暫停)
- 遠程節點可能已經處理了請求,但是網絡上的響應已經丟失
- 遠程節點可能已經處理了請求,但是響應已經被延遲,並且稍後將被傳遞
- 網路特性
- 不確定: 網絡擁塞和排隊
- 不可靠: 掉包
- 都是為了讓網路利用最大化
- 對比: 電信網路
- 一次占用一個線路
- 線路速度固定 (在空閒時不能多用!!)
- 對比: 電信網路
- 緩和的方法
- 檢測故障 (把遠程節點關閉)
- 特定的方法
- 如果節點進程崩潰(或被管理員殺死),但節點的操作系統仍在運行,則腳本可以通知其他節點有關該崩潰的信息
- 如果你有權訪問數據中心網絡交換機的管理界面,則可以通過它們檢測硬件級別的鏈路故障
- general
- 重複送、timeout (但sender還是不知道發生什麼了)
- timout要多久?
- timeout短: 可能把正在跑的殺了 (之後可能cascade)
- timeout長: 效能
- 用algo根據response time去動態調
- timout要多久?
- 重複送、timeout (但sender還是不知道發生什麼了)
- 特定的方法
- 檢測故障 (把遠程節點關閉)
- 發送請求並期待響應,則很多事情可能會出錯 (不會知道對面發生什麼事導致lost)
- 不可靠的時鐘
- 我們想透過時間知道
- 持續時間
- 單調鐘 (物理時鐘)
- 保證總是往前走的事實
- 在多顆cpu下,OS會試著保證單調鐘的性質
- 但還是保持懷疑的態度比較好
- 單調鐘 (物理時鐘)
- 時間點
- 日歷時鐘 (物理時鐘)
- NTP同步有誤差,可能會回跳
- 邏輯時鐘(logic clock)
- 用計數器遞增
- 日歷時鐘 (物理時鐘)
- 持續時間
- 時鐘讀數存在置信區間
- 因為誤差
- 這樣能用物理時鐘作快照隔離transaction的id嗎?
- google Spanner
- 要確保小的時鐘不確定性
- commit之前等一段時間 (置信區間)
- google Spanner
- 進程暫停
- 自己看到的東西與別人認為的不同
- 因進程暫停導致自己以為
- 我還是leader
- 我的timer還沒到期 (像lease到期)
- 進程暫停的可能原因
- preempt process
- GC
- page fault導致的IO
- IO
- vm suspend
- 注意
- 分布式系統中的節點,必須假定其執行可能在任意時刻暫停相當長的時間,即使是在一個函數的中間
- 可能的努力
- hard real-time: 需要OS與各種程式的保證
- 限制垃圾收集
- 將GC暫停視為一個節點的短暫計劃中斷,並在這個節點收集其垃圾的同時,讓其他節點處理來自客戶端的請求
- 只用垃圾收集器來處理短命對象,並定期在積累大量長壽對象(因此需要完整GC)之前重新啟動進程
- 防護令牌(fencing token)
- 這個數字在每次授予鎖(lease)定時都會增加
- 然後,我們可以要求客戶端每次向存儲服務發送寫入請求時,都必須包含當前的防護令牌
- 我們想透過時間知道
- 知識、真相與謊言
- 節點不一定能相信自己對於情況的判斷
- node可能突然智障
- 在航空航天環境中,計算機內存或CPU寄存器中的數據可能被輻射破壞,導致其以任意不可預知的方式響應其他節點
- 有不信任的點
- 解
- 法定人數,即在節點之間進行投票
- 防止“撒謊”弱形式的機制
- 對輸入檢查
- CRC
- escape
- 對輸入檢查
- 算法的正確性
- 如果某些假設爆了,最少有哪些特性要保持?
- 安全(safety)屬性
- 沒有壞事發生
- 如果安全屬性被違反,我們可以指向一個特定的安全屬性被破壞的時間點
- 活性(liveness)屬性
- 最終好事發生
- 在某個時間點,它可能不成立,但總是希望在未來能成立
- 在系統模型的所有可能情況下,要求始終保持安全屬性是常見的
- 對於活性屬性,我們可以提出一些注意事項
- 安全(safety)屬性
- 如果某些假設爆了,最少有哪些特性要保持?
- 系統模型與現實
- 時序假設
- 同步模型(synchronous model)
- 假設網絡延遲、進程暫停和和時鐘誤差都是受限的
- 網絡延遲、暫停和時鐘漂移將永遠不會超過某個固定的上限
- 部分同步(partial synchronous)
- 一個系統在大多數情況下像一個同步系統一樣運行,但有時候會超出網絡延遲,進程暫停和時鐘漂移的界限
- 異步模型
- 一個算法不允許對時序做任何假設——事實上它甚至沒有時鐘(所以它不能使用超時)
- 同步模型(synchronous model)
- 節點失效
- 崩潰停止(crash-stop)
- 算法可能會假設一個節點只能以一種方式失效,即通過崩潰
- 崩潰-恢覆(crash-recovery)
- 我們假設節點可能會在任何時候崩潰,但也許會在未知的時間之後再次開始響應
- 拜占庭(任意)故障
- 節點可以做(絕對意義上的)任何事情,包括試圖戲弄和欺騙其他節點
- 崩潰停止(crash-stop)
- 將系統模型映射到現實世界
- 算法的理論描述可以簡單宣稱一些事是不會發生的
- 在非拜占庭式系統中,我們確實需要對可能發生和不可能發生的故障做出假設
- 真實世界的實現,仍然會包括處理“假設上不可能”情況的代碼
- printf(“Sucks to be you”)和exit(666)
- 算法的理論描述可以簡單宣稱一些事是不會發生的
- 時序假設
第九章:一致性與共識
構建容錯系統的最好方法,是找到一些帶有實用保證的通用抽象,實現一次,然後讓應用依賴這些保證
通過使用事務,應用可以假裝沒有崩潰(原子性),沒有其他人同時訪問數據庫(隔離),存儲設備是完全可靠的(持久性)
分布式系統最重要的抽象之一就是共識(consensus):就是讓所有的節點對某件事達成一致
在與只提供弱保證的數據庫打交道時,你需要始終意識到它的局限性,而不是意外地作出太多假設
在與只提供弱保證的數據庫打交道時,你需要始終意識到它的局限性,而不是意外地作出太多假設
盡管兩者有一部分內容重疊,但它們大多是無關的問題:事務隔離主要是為了避免由於同時執行事務而導致的競爭狀態,而分布式一致性主要關於在面對延遲和故障時如何協調副本間的狀態
線性一致性(linearizability)
- 讓一個系統看起來好像只有一個數據副本,而且所有的操作都是原子性的
- 線性一致性是一個新鮮度保證(recency guarantee)
- 在一個線性一致的系統中,我們可以想象,在 x 的值從0 自動翻轉到 1 的時候(在寫操作的開始和結束之間)必定有一個時間點
- cas成功的時候
- 線性一致性與可串行化
- 可串行化(Serializability)
- 事務的隔離屬性
- 它確保事務的行為,與它們按照某種順序依次執行的結果相同
- 線性一致性(Linearizability)
- 讀取和寫入寄存器(單個對象)的新鮮度保證
- 它不會將操作組合為事務,因此它也不會阻止寫入偏差等問題
- 可串行 imply 線性一致?
- 基於兩階段鎖定的可串行化實現或真的串行執行通常是線性一致性的
- 可串行化的快照隔離不是線性一致性的
- 它從一致的快照中進行讀取,以避免讀者和寫者之間的鎖競爭
- 一致性快照的要點就在於它不會包括該快照之後的寫入,因此從快照讀取不是線性一致性的。
- 可串行化(Serializability)
- scnerio
- 鎖定和領導選舉
- 約束和唯一性保證
- 跨信道的時序依賴
- 實現線性一致的系統 (副本)
- 單主覆制
- 可能線性一致
- 一個節點很可能會認為它是領導者,而事實上並非如此
- 可能線性一致
- 共識算法
- 線性一致
- 防止腦裂和陳舊副本的措施
- 線性一致
- 多主覆制
- 非線性一致
- LWW與沒有固定資料來源
- 非線性一致
- 無主覆制
- 也許不是線性一致的
- 有網路延遲就會讓write變慢,這樣就有可能讀到舊的
- 做讀修復就可以保持線性一致 (client看到新的就寫回去舊的source)
- 只能實現線性一致的讀寫
- 不能實現線性一致的比較和設置(CAS)操作
- 因為它需要一個共識算法
- 做讀修復就可以保持線性一致 (client看到新的就寫回去舊的source)
- 寬松的法定人數
- 有網路延遲就會讓write變慢,這樣就有可能讀到舊的
- 也許不是線性一致的
- 單主覆制
- 線性一致性的代價
- 網絡中斷迫使在線性一致性和可用性之間做出選擇
- 為了提高性能而選擇了犧牲線性一致性,而不是為了容錯
- 如果你想要線性一致性,讀寫請求的響應時間至少與網絡延遲的不確定性成正比
- 讓一個系統看起來好像只有一個數據副本,而且所有的操作都是原子性的
順序保證
- 順序反覆出現有幾個原因,其中一個原因是,它有助於保持因果關系(causality)
- 因果一致(causally consistent)
- 一個系統服從因果關系所規定的順序
- 快照隔離提供了因果一致性:當你從數據庫中讀取到一些數據時,你一定還能夠看到其因果前驅
- 因果順序不是全序的 (有併發的事件所以沒有全序)
- 線性一致性強於因果一致性
- 線性一致性
- 在線性一致的系統中,操作是全序的 (表現的就好像只有一個數據副本)
- 因果性
- 兩個事件是因果相關的(一個發生在另一個事件之前),則它們之間是有序的
- 它們是並發的,則它們之間的順序是無法比較的
- 線性一致性隱含著(implies) 因果關系
- 許多情況下,看上去需要線性一致性的系統,實際上需要的只是因果一致性,因果一致性可以更高效地實現
- 線性一致性
- 線性一致性強於因果一致性
- 捕獲因果關系
- 為了確定因果依賴,我們需要一些方法來描述系統中節點的“知識”
- 如果節點在發出寫入Y 的請求時已經看到了 X的值,則 X 和 Y 可能存在因果關系
- 在檢測並發寫入時看到的版本向量
- 是檢測到對同一個鍵的並發寫入
- 所以需要一個更高維的版本來跟蹤整個數據庫中的因果依賴
- 為了確定因果依賴,我們需要一些方法來描述系統中節點的“知識”
- 一個系統服從因果關系所規定的順序
- 序列號順序
- 雖然因果是一個重要的理論概念,但實際上跟蹤所有的因果關系是不切實際的
- 改用序列號順序
- 使用序列號(sequence nunber) 或時間戳(timestamp) 來排序事件
- 改用序列號順序
- 每個操作都有一個唯一的序列號,而且總是可以比較兩個序列號,確定哪一個更大
- 與因果一致(consistent with causality) 的全序
- 並行操作之間可以任意排序。這樣一個全序關系捕獲了所有關於因果的信息,但也施加了一個比因果性要求更為嚴格的順序
- 蘭伯特時間戳 (Lamport)
- 蘭伯特時間戳就是兩者的簡單組合:(計數器,節點ID)
- 蘭伯特時間戳與物理的日歷時鐘沒有任何關系,但是它提供了一個全序:如果你有兩個時間戳,則計數器值大者是更大的時間戳
- 作法
- 每個節點和每個客戶端跟蹤迄今為止所見到的最大計數器值,並在每個請求中包含這個最大計數器值
- 當一個節點收到最大計數器值大於自身計數器值的請求或響應時,它立即將自己的計數器設置為這個最大值。
- 蘭伯特時間戳 & 版本向量
- 版本向量可以區分兩個操作是並發的,還是一個因果依賴另一個
- 蘭伯特時間戳總是施行一個全序
- 無法分辨兩個操作是並發的還是因果依賴的
- 光有時間戳排序還不夠
- 只有在所有的操作都被收集之後,操作的全序才會出現 (當下不會知道)
- 為了實現諸如用戶名上的唯一約束這種東西
- 僅有操作的全序是不夠的
- 你還需要知道這個全序何時會塵埃落定
- 全序廣播
- 為了實現諸如用戶名上的唯一約束這種東西
- 只有在所有的操作都被收集之後,操作的全序才會出現 (當下不會知道)
- 與因果一致(consistent with causality) 的全序
- 雖然因果是一個重要的理論概念,但實際上跟蹤所有的因果關系是不切實際的
全序廣播
- 順序在消息送達時被固化
- 如果後續的消息已經送達,節點就不允許追溯地將(先前)消息插入順序中的較早位置
- 這個事實使得全序廣播比時間戳排序更強
- 要滿足兩個安全屬性
- 可靠交付(reliable delivery)
- 沒有消息丟失:如果消息被傳遞到一個節點,它將被傳遞到所有節點
- 全序交付(totally ordered delivery)
- 消息以相同的順序傳遞給每個節點
- 可靠交付(reliable delivery)
- 消息被保證以固定的順序可靠地傳送,但是不能保證消息何時被送達
- 可以使用全序廣播來實現可串行化的事務
- 每個消息都代表一次數據庫的寫入,且每個副本都按相同的順序處理相同的寫入
- 那麽副本間將相互保持一致(除了臨時的覆制延遲)
- 這個原理被稱為狀態機覆制
- 那麽副本間將相互保持一致(除了臨時的覆制延遲)
- 每個消息都代表一次數據庫的寫入,且每個副本都按相同的順序處理相同的寫入
- 使用全序廣播實現線性一致的存儲
- 從形式上講,線性一致讀寫寄存器是一個“更容易”的問題
- 全序廣播等價於共識
- 共識問題在異步的崩潰-停止模型中沒有確定性的解決方案
- 線性一致的讀寫寄存器可以在這種模型中實現
- 支持諸如比較並設置(CAS, compare-and-set),或自增並返回(increment-and-get) 的原子操作使線性一致等價於共識問題
- 作法
- 寫入線性一致
- 在log加消息claim要加資料
- 讀日志,並等待你剛才追加的消息被讀回
- 如果第一筆是你的req就可以commit,不然就abort
- 讀取線性一致
- 在log加消息claim要讀資料
- 讀日志,並等待你剛才追加的消息被讀回,有了就去讀
- 寫入線性一致
- 從形式上講,線性一致讀寫寄存器是一個“更容易”的問題
- 使用線性一致性存儲實現全序廣播
- 作法
- 每個要通過全序廣播發送的消息首先對線性一致寄存器執行自增並返回操作
- 你對線性一致性的序列號生成器進行過足夠深入的思考,你不可避免地會得出一個共識算法
- 然後將從寄存器獲得的值作為序列號附加到消息中
- 然後你可以將消息發送到所有節點(重新發送任何丟失的消息),而收件人將按序列號依序傳遞(deliver)消息
- 每個要通過全序廣播發送的消息首先對線性一致寄存器執行自增並返回操作
- 作法
- 順序在消息送達時被固化
分布式事務與共識
- 場景
- 領導選舉
- 原子提交
- 兩階段提交(two-phase commit)
- 用於實現跨多個節點的原子事務提交的算法,即確保所有節點提交或所有節點中止
- 當應用準備提交時,協調者開始階段 1 :它發送一個準備(prepare) 請求到每個節點,詢問它們是否能夠提交
- 如果所有參與者都回答“是”,表示它們已經準備好提交,那麽協調者在階段 2 發出提交(commit) 請求
- 兩個關鍵的“不歸路”點
- 當參與者投票“是”時,它承諾它稍後肯定能夠提交
- 一旦協調者做出決定,這一決定是不可撤銷的
- 協調者失效
- 只能等待協調者自己好
- 讓管理員手動決定提交還是回滾事務
- 關心存疑事務?
- 數據庫事務通常獲取待修改的行上的行級排他鎖,以防止臟寫
- 用於實現跨多個節點的原子事務提交的算法,即確保所有節點提交或所有節點中止
- 場景
容錯共識
- 特點
- 一致同意(Uniform agreement): 沒有兩個節點的決定不同。
- 完整性(Integrity): 沒有節點決定兩次。
- 有效性(Validity): 如果一個節點決定了值 v ,則 v 由某個節點所提議
- 終止(Termination): 由所有未崩潰的節點來最終決定值。
- 方法
- 如果你不關心容錯,那麽滿足前三個屬性很容易:你可以將一個節點硬編碼為“獨裁者”,並讓該節點做出所有的決定
- 它實質上說的是,一個共識算法不能簡單地永遠閑坐著等死
- 如果你不關心容錯,那麽滿足前三個屬性很容易:你可以將一個節點硬編碼為“獨裁者”,並讓該節點做出所有的決定
- 全序廣播相當於重覆進行多輪共識
- 限制
- 共識系統總是需要嚴格多數來運轉
- 大多數共識算法假定參與投票的節點是固定的集合
- 共識系統通常依靠超時來檢測失效的節點
- 特點
第十章:批處理
使用MapReduce編程模型,能將計算的物理網絡通信層面(從正確的機器獲取數據)從應用邏輯中剝離出來(獲取數據後執行處理)
- MapReduce作業執行
- 讀folder
- hadoop: 將計算放在數據附近 (copy code過去)
- DB: 把資料拉回來
- map: 分類(加上key)
- Map任務的數量由輸入文件塊的數量決定
- reduce: 根據key做運算 & 合併 & sort!!
- Reducer的任務的數量是由作業作者配置
- 放到folder
- 讀folder
- MapReduce工作流
- 一個作業的輸出成為下一個作業的輸入
- 通過目錄名隱式實現
- 會產生臨時文件 (物化臨時狀態)
- 之後被copy到其他node!!
- 所以之後有spark把整個workflow當成一個task的框架
- 同時所有資料都在mem
- 這樣retry很容易
- 因為資料是持久化的
- 之後被copy到其他node!!
- 會產生臨時文件 (物化臨時狀態)
- 通過目錄名隱式實現
- 一個作業的輸出成為下一個作業的輸入
- Reduce側連接與分組 (join in reduce)
- 排序合並連接(sort-merge join)
- 把要join的資料先載回來,sort
- 之後就可以join
- 分組
- mapper用同一個key
- Reduce側方法的
- 優點
- 不需要對輸入數據做任何假設:無論其屬性和結構如何,Mapper都可以對其預處理以備連接
- 缺點
- 排序,覆制至Reducer,以及合並Reducer輸入,所有這些操作可能開銷巨大
- 優點
- 排序合並連接(sort-merge join)
- 處理偏斜
- reducer會變成熱點
- 由於MapReduce作業只有在所有Mapper和Reducer都完成時才完成,所有後續作業必須等待最慢的Reducer才能啟動
- 偏斜連接(skewed join)
- 首先運行一個抽樣作業(Sampling Job)來確定哪些鍵是熱鍵
- 連接實際執行時,Mapper會將熱鍵的關聯記錄隨機(相對於傳統MapReduce基於鍵散列的確定性方法)發送到幾個Reducer之一
- 對於另外一側的連接輸入,與熱鍵相關的記錄需要被覆制到所有處理該鍵的Reducer上
- reducer會變成熱點
- Map側連接
- 如果你能對輸入數據作出某些假設,則通過使用所謂的Map側連接來加快連接速度是可行的
- 廣播散列連接(broadcast hash join)
- 把小數據集放到map的hash table,之後join
- 另一種方法是將較小輸入存儲在本地磁盤上的只讀索引中
- 把小數據集放到map的hash table,之後join
- 桶連接(bucketed map joins)
- 把資料分類再跑broadcast hash join
- Mapper3首先將所有具有以3結尾的ID的用戶加載到散列表中,然後掃描ID為3的每個用戶的所有活動事件
- 把資料分類再跑broadcast hash join
- Map側合並連接
- 如果輸入數據集不僅以相同的方式進行分區,而且還基於相同的鍵進行排序
- 在這種情況下,輸入是否小到能放入內存並不重要
- 因為這時候Mapper同樣可以執行歸並操作(通常由Reducer執行)的歸並操作
- 如果輸入數據集不僅以相同的方式進行分區,而且還基於相同的鍵進行排序
- 針對頻繁故障設計
- MapReduce可以容忍單個Map或Reduce任務的失敗,而不會影響作業的整體,通過以單個任務的粒度重試工
- 它也會非常急切地將數據寫入磁盤,一方面是為了容錯,另一部分是因為假設數據集太大而不能適應內存
第十一章:流處理
為了減少延遲,我們可以更頻繁地運行處理 —— 比如說,在每秒鐘的末尾 —— 或者甚至更連續一些,完全拋開固定的時間切片,當事件發生時就立即進行處理,這就是流處理(stream processing)
記錄通常被叫做 事件(event) ,但它本質上是一樣的:一個小的、自包含的、不可變的對象,包含某個時間點發生的某件事情的細節。一個事件通常包含一個來自日歷時鐘的時間戳,以指明事件發生的時間
一個事件由 生產者(producer)生成一次,然後可能由多個 消費者(consumer)進行處理
在某些系統中,網絡延遲可能低於磁盤訪問延遲,網絡帶寬也可能與磁盤帶寬相當。沒有針對所有情況的普適理想權衡,隨著存儲和網絡技術的發展,本地狀態與遠程狀態的優點也可能會互換。
- 消息傳遞系統(messaging system)
- 生產者發送包含事件的消息,然後將消息推送給消費者
- 兩個問題
- 如果生產者發送消息的速度比消費者能夠處理的速度快會發生什麽
- 系統可以丟掉消息
- 將消息放入緩沖隊列
- 使用背壓 (有限的queue)
- 如果節點崩潰或暫時脫機,會發生什麽情況? —— 是否會有消息丟失?
- 如果生產者發送消息的速度比消費者能夠處理的速度快會發生什麽
- 傳送方式
- 直接從生產者傳遞給消費者
- 它們通常要求應用代碼意識到消息丟失的可能性
- 它們通常也只是假設生產者和消費者始終在線
- 當生產者崩潰時,它可能會丟失消息緩沖區及其本應發送的消息,這種方法可能就沒用了
- 消息代理
- 消息代理實質上是一種針對處理消息流而優化的數據庫
- 持久性問題則轉移到代理的身上
- 消息代理與數據庫的對比
- 刪除
- 數據庫通常保留數據直至顯式刪除
- 大多數消息代理在消息成功遞送給消費者時會自動刪除消息
- 工作集
- 由於它們很快就能刪除消息,大多數消息代理都認為它們的工作集相當小
- 如果代理需要緩沖很多消息,每個消息需要更長的處理時間,整體吞吐量可能會惡化
- search
- 數據庫通常支持次級索引和各種搜索數據的方式
- 消息代理通常支持按照某種模式匹配主題
- query
- 查詢數據庫時,結果通常基於某個時間點的數據快照
- 消息代理不支持任意查詢,但是當數據發生變化時,它們會通知客戶端
- 刪除
- 直接從生產者傳遞給消費者
- 消息傳遞模式
- 負載均衡(load balancing)
- 每條消息都被傳遞給消費者之一
- 扇出(fan-out)
- 每條消息都被傳遞給所有消費者
- 負載均衡(load balancing)
- 確認與重新傳遞
- 為了確保消息不會丟失,消息代理使用確認(acknowledgments)
- 如果與客戶端的連接關閉,或者代理超出一段時間未收到確認,代理則認為消息沒有被處理,因此它將消息再遞送給另一個消費者。
- 但其實有可能已經被處理完了!! (ack可能被drop)
- 即使消息代理試圖保留消息的順序,負載均衡與重傳的組合也不可避免地導致消息被重新排序!!
- 基於日志的消息代理(log-based message brokers)
- 使用日志進行消息存儲
- 生產者通過將消息追加到日志末尾來發送消息
- 消費者通過依次讀取日志來接收消息
- 為了伸縮超出單個磁盤所能提供的更高吞吐量
- 可以對日志進行分區(按第六章的定義)
- 不同的分區可以托管在不同的機器上
- 使得每個分區都有一份能獨立於其他分區進行讀寫的日志
- 在每個分區內,代理為每個消息分配一個單調遞增的序列號或偏移量
- 所有偏移量小於消費者的當前偏移量的消息已經被處理,而具有更大偏移量的消息還沒有被看到
- 代理不需要跟蹤確認每條消息,只需要定期記錄消費者的偏移即可
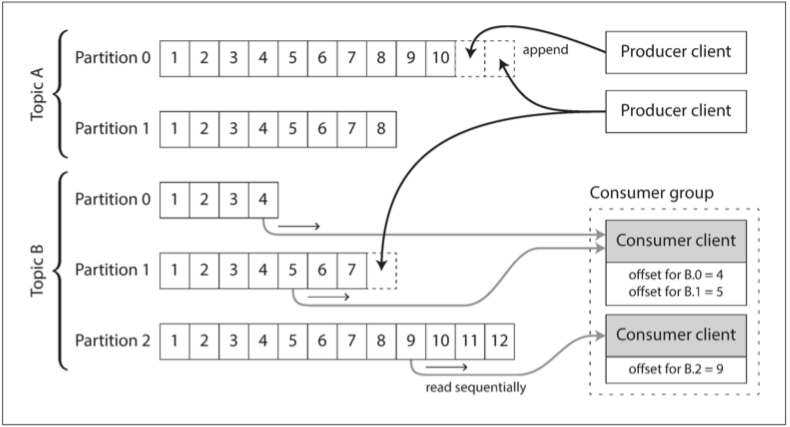
- 日志與傳統的消息傳遞相比
- 為了在一組消費者之間實現負載平衡
- 代理可以將整個分區分配給消費者組中的節點
- 而不是將單條消息分配給消費者客戶端
- 代理可以將整個分區分配給消費者組中的節點
- 每個客戶端將消費被指派分區中的所有消息
- 共享消費主題工作的節點數,最多為該主題中的日志分區數
- 如果某條消息處理緩慢,則它會阻塞該分區中後續消息的處理
- 為了在一組消費者之間實現負載平衡
- 磁盤空間使用
- 為了回收磁盤空間,日志實際上被分割成段
- 如果一個慢消費者跟不上消息產生的速率而落後得太多
- 它的消費偏移量指向了刪除的段,那麽它就會錯過一些消息
- 你可以監控消費者落後日志頭部的距離,如果落後太多就發出報警。
- 由於緩沖區很大,因而有足夠的時間來修覆慢消費者
- 它的消費偏移量指向了刪除的段,那麽它就會錯過一些消息
- 如果一個慢消費者跟不上消息產生的速率而落後得太多
- 為了回收磁盤空間,日志實際上被分割成段
- 重播舊消息
- 除了消費者的任何輸出之外,處理的唯一副作用是消費者偏移量的前進
- 把DB當成message brokers
- redo log當成message
- 變更數據捕獲(change data capture, CDC)
- 紀錄底層的狀態變更
- 存儲在搜索索引和數據倉庫中的數據,只是記錄系統數據的額外視圖
- 存儲在搜索索引和數據倉庫中的數據,只是記錄系統數據的額外視圖
- 變更數據捕獲通常是異步的
- 添加緩慢的消費者不會過度影響記錄系統
- 所有覆制延遲可能有的問題在這里都可能出現
- 事件溯源(Event Sourcing)
- 應用邏輯顯式構建在寫入事件日志的不可變事件之上
- 事件通常表示用戶操作的意圖,而不是因為操作而發生的狀態更新機制
- 所以你需要完整的歷史事件來重新構建最終狀態
- 這里進行同樣的日志壓縮是不可能的
- 事件通常表示用戶操作的意圖,而不是因為操作而發生的狀態更新機制
- 仔細區分事件(event) 和命令(command)
- 用戶的請求剛到達時,它一開始是一個命令
- 可能失敗
- 如果驗證成功並且命令被接受,則它變為一個持久化且不可變的事件
- 在事件生成的時刻,它就成為了事實(fact)
- 用戶的請求剛到達時,它一開始是一個命令
- 應用邏輯顯式構建在寫入事件日志的不可變事件之上
- 並發控制
- 事件溯源和變更數據捕獲的最大缺點是,事件日志的消費者通常是異步的,所以可能會
- 用戶會寫入日志,然後從日志衍生視圖中讀取,結果發現他的寫入還沒有反映在讀取視圖中
- 一種解決方案是將事件追加到日志時同步執行讀取視圖的更新
- 需要事務
- 事件溯源和變更數據捕獲的最大缺點是,事件日志的消費者通常是異步的,所以可能會
- 變更數據捕獲(change data capture, CDC)
- redo log當成message
- 使用日志進行消息存儲
- 流處理
- 特色
- 當查詢進入時,數據庫搜索與查詢匹配的數據,然後在查詢完成時丟掉查詢
- 分析往往對找出特定事件序列並不關心,而更關注大量事件上的聚合與統計指標
- 構建物化視圖可能需要任意時間段內的所有事件,除了那些可能由日志壓縮丟棄的過時事件
- 查詢被存儲下來,文檔從查詢中流過
- 事件時間與處理時間
- 測量請求速率,按處理時間來衡量速率
- 如果你重新部署流處理器,它可能會停止一分鐘,並在恢覆之後處理積壓的事件
- 請求速率看上去就像有一個異常的突發尖峰
- 實際上請求速率是穩定的
- 要統計的方式思考、而不是取樣的方式思考
- 測量請求速率,按處理時間來衡量速率
- 知道什麽時候準備好了
- 你永遠也無法確定是不是已經收到了特定窗口的所有事件,還是說還有一些事件正在來的路上
- 忽略這些滯留事件
- 發布一個更正(correction),一個包括滯留事件的更新窗口值
- 在某些情況下,可以使用特殊的消息來指示“從現在開始,不會有比t更早時間戳的消息了”
- 你永遠也無法確定是不是已經收到了特定窗口的所有事件,還是說還有一些事件正在來的路上
- 你用的是誰的時鐘?
- 事件上的事件戳實際上應當是用戶交互發生的時間,取決於移動設備的本地時鐘
- 本地時鐘可能改過
- 方法
- 記錄三個時間戳
- 事件發生的時間,取決於設備時鐘
- 事件發送往服務器的時間,取決於設備時鐘
- 事件被服務器接收的時間,取決於服務器時鐘
- 通過從第三個時間戳中減去第二個時間戳,可以估算設備時鐘和服務器時鐘之間的偏移
- 然後可以將該偏移應用於事件時間戳,從而估計事件實際發生的真實時間
- 記錄三個時間戳
- 事件上的事件戳實際上應當是用戶交互發生的時間,取決於移動設備的本地時鐘
- 窗口的類型
- 滾動窗口(Tumbling Window)
- 滾動窗口有著固定的長度,每個事件都僅能屬於一個窗口
- 跳動窗口(Hopping Window)
- 跳動窗口也有著固定的長度,但允許窗口重疊以提供一些平滑
- 滑動窗口(Sliding Window)
- 滑動窗口包含了彼此間距在特定時長內的所有事件
- 會話窗口(Session window)
- 將同一用戶出現時間相近的所有事件分組在一起,而當用戶一段時間沒有活動時窗口結束
- 滾動窗口(Tumbling Window)
- 特色
- 不變性的局限性
- 永遠保持所有變更的不變歷史,在多大程度上是可行的?
- 答案取決於數據集的流失率
- 數據集上有較高的更新/刪除率,不可變的歷史可能增至難以接受的巨大
- 碎片化可能成為一個問題,壓縮與垃圾收集的表現對於運維的穩健性變得至關重
- 數據集上有較高的更新/刪除率,不可變的歷史可能增至難以接受的巨大
- 答案取決於數據集的流失率
- 不能做到真正的刪除
- 隱私條例可能要求在用戶關閉帳戶後刪除他們的個人信息
- 但副本可能存在於很多地方
- 永遠保持所有變更的不變歷史,在多大程度上是可行的?
- 冪等性
- 丟棄任何失敗任務的部分輸出,以便能安全地重試,而不會生效兩次
- 分布式事務
- 依賴冪等性(idempotence)
- 依賴冪等性意味著隱含了一些假設
- 重啟一個失敗的任務必須以相同的順序重播相同的消息,處理必須是確定性的,沒有其他節點能同時更新相同的值
- 丟棄任何失敗任務的部分輸出,以便能安全地重試,而不會生效兩次
- 雙寫(dual write)的問題
- 如果周期性的完整數據庫轉儲過於緩慢,有時會使用的替代方法是雙寫
- 應用代碼在數據變更時明確寫入每個系統 (DB, search index…)
- 雙寫有一些嚴重的問題
- 競爭條件 (並發檢測機制: 版本向量)
- 其中一個寫入可能會失敗,而另一個成功 (原子提交)
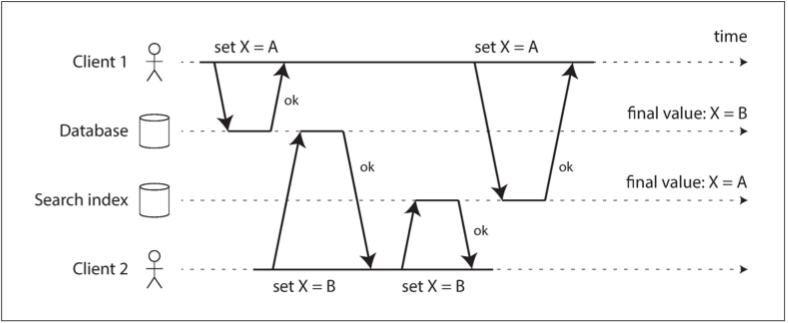
- 如果周期性的完整數據庫轉儲過於緩慢,有時會使用的替代方法是雙寫
第十二章:數據系統的未來
skip