動機
整理一下
總體而言
在任何時間點,於不能反悔的情況下維持共識
paxos與其他共識演算法都是在保護上面假設
實際如何執行?
- 不能反悔 (資料保持最新 & 承認時間流逝)
- 遞增
- 冪等
- immutation
- 共識
- 多數決
- 單一來源
- 描述時間
- 序列號
下面根據paper的時間線來看
- basic paxos
- multi-paxos
- zab
- raft
basic paxos
有兩個角色,proposer與accepter (對應到raft是leader與follower)
之後與raft不同的是paxos可以同時管理好幾個app的狀態(所以paxos可以接受不連續的log,因為log不用遞增)
在paxos就是value去區分,每個value都會帶有一個只能遞增的rnd,與當前acceptor知道的最後一個rnd(log的最後index)
paxos的proposer是任何人都能當的,但要怎麼確認自己的提案會不會被接受?
所以proposer要先問過半的accepter的最大rnd(prepare)
同時acceptor設定之後預期看到的rnd,也就是last_rnd
在下面的圖,log entry整個大概是(last_rnd, value[vrnd])
另外,記得last_rnd不論何時一定大於等於vrnd 不論在什麼階段,prepare或是accept
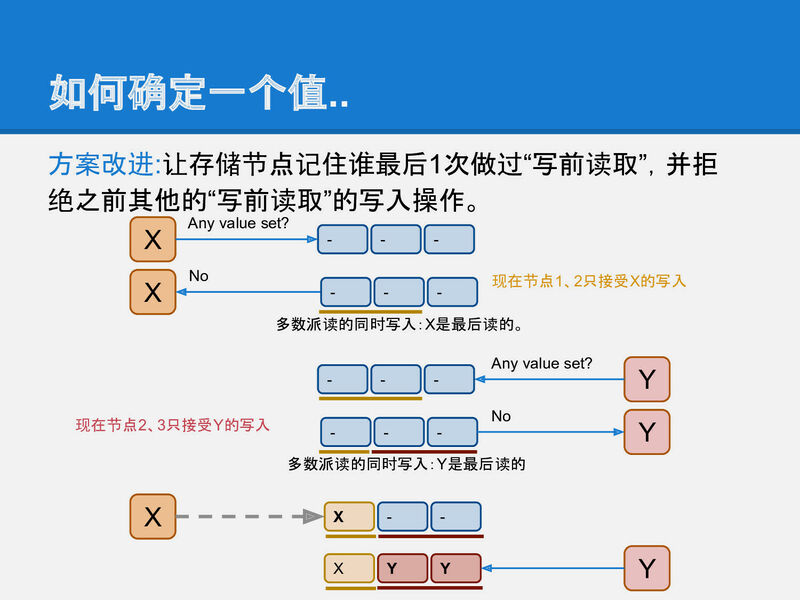


(假設還有其他資料,像是log,就要再額外sync,見zab,不過basic paxos沒有所以這段上括號)
之後才傳資料,只要rnd(aka log)對的上就收(accept)。
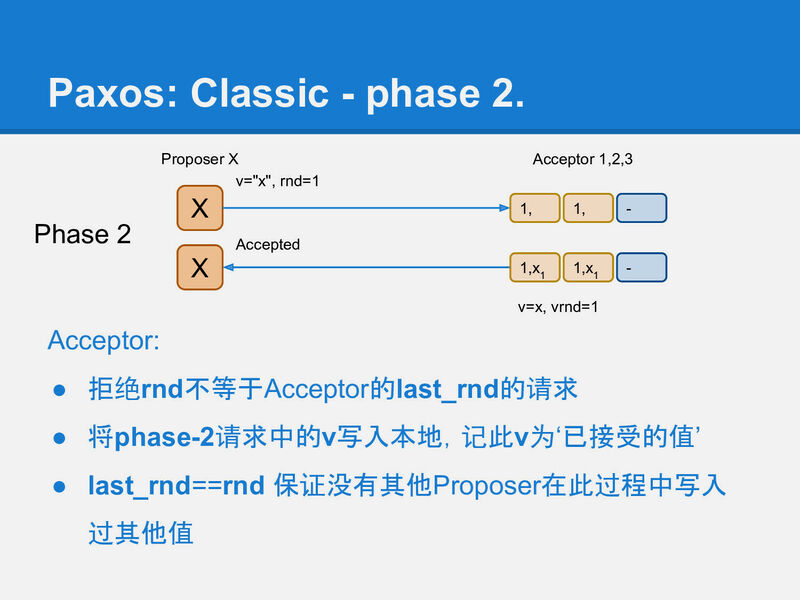
另外paxos這樣可能會產生livelock,只要有兩個proposer打同一個value就會產生,所以要區隔時間(raft的election timer)
到此,classic paxos可以看成quorum + 2 phase commit 原本的2 phase commit要所有人確認,但因為這是共識只要quorum到就好
定義quorum
為什麼要到quorum? 因為這樣可以確保任意讀與寫至少都會有一個有對的資料
如果只是要符合"至少都會有一個有對的資料",這樣一定要過半嗎? 不用,像是
- 要求每個quorum都包含一個特定點
- 分階層,要求quorum至少要跨一行與跨一欄
- 只有兩行,要求包含第一行的majority, 或在每一行都包含一个majority
這樣有什麼好處與壞處? 好處: 可以以較少的數量達成quorum,如此一來可以選近的 或是 發少一點rpc 壞處: 犧牲avaibility,像是只要是包含的那個唯一的點壞了就出事了;但過半可以讓另一半壞了也ok
正確性
value的rnd保證不反悔app狀態同時代表時間點 先問過半的accepter的最大id確保app狀態共識
multi-paxos
如果說每次都要同步log才能傳資料就很麻煩另外還有livelock的風險 所以把proposer定成一個這樣就能省下同步log的步驟
正確性
proposer只要有最新的id,之後就可以commit到acceptor,等commit完成後就proposer又會有最新的id (遞迴)
fast paxos
真的不想prepare!! 那就直接寫,用最小的rnd去寫。
失敗的話,還是要prepare阿 有沒有辦法在報錯時確認當前的quorum是什麼?
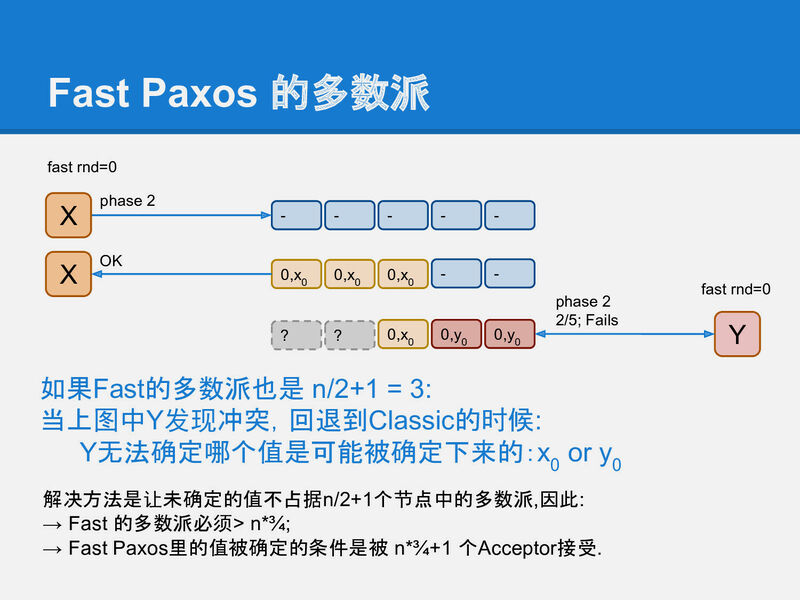
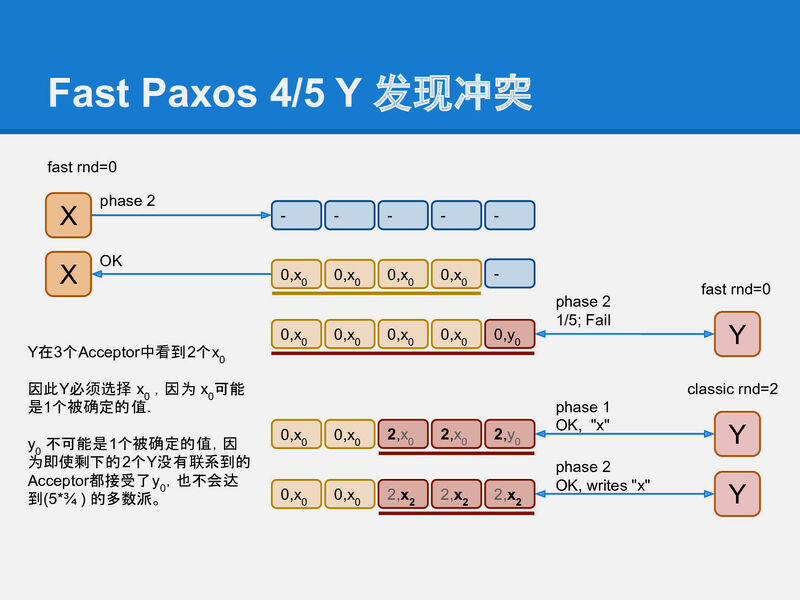
所以quorum要變成3/4
zab
就是multi-paxos + 選leader
但這樣打太短要補一點東西
zab分成4個階段
- election
- 透過zxid來選其實就是
- term (這裡叫epoch)
- id (就是paxos的id)
- 之後記住自己投給誰
- discovery (prepare)
- sync (sync log)
- braodcast (accept)
選leader的正確性
leader會壞怎麼辦?
- 選leader也要在任何時間點,於不能反悔的情況下維持共識
- 所以多了term與voteFor,term表示時間、voreFor就是資料
raft
如果只有一個app要管而已,可以簡化設計嗎?
- 只放一個log,那可以直接用log遞增取代id
- 只有一個log,可以在選leader直接認最新log的為leader
- 也因此,同步log的時機與paxos不同
- paxos因為任何人都可以當proposer,所以一開始就要sync log
- raft是在成為leader之後才透過appendEntries同步log
- 但可能有不一致的log,所以才有figure 8
整個dataflow可以看成 leader -> log
因為leader要過半,所以是共識; 認leader自然imply認log; (appendEntries) 接著就是認leader不能反悔; 最後就是commit出去的不能變,所以有過半才能commit;
但是只有這樣會產生figure 8的問題,所以要多一個條件 只能在同一個term完成同一個term的事件
因為只有在完成appendEntrries之後才能確認,follower的log與leader同步,而唯一能讓leader發appendEntrries只有新log或是heartbeat。
正確性
- 不能反悔
- term只能遞增
- 只能在同一個term完成同一個term的事件 (第一個處理亂序與crash的手法)
- leader的log只能遞增
- 共識
- 每個term的leader最多一個
- 用誰的log比較新決定leader
- 認term與log對不對得起來
- 用誰的log比較新決定leader
- leader持有夠新的log且過半(一樣新或是比較舊)
- log最新的log會過半
- 有新log會reject其他candidate
- follower會與leader的log同步
- merge相符但是比較短的entries (第二個處理亂序的手法)
- 砍掉開始不一樣的log
- log最新的log會過半
- 過半才做下一個步驟
- 成為leader (leader最多一個)
- commit log上去 (確定新的log占多數)
- 在同一個term完成同一個term的事件 (raft獨有)
- figure 8
- 因為是等到appendEntrries才sync log (類似lazy eval)
- 變成只能在自己的term才能確認log是對的
- 但是只要確認就能利用 multi-paxos的遞迴 確認前面的log也是對的!!
abstract-paxos
将 paxos 和 raft 统一到一个协议下: abstract-paxos
這篇就是把原po的quorum與paxos組合在一起,從phase2開始講到phase1
先有兩個腳色,reader與writer
我們的algo要保證下面的性質
- commit-寫quorum: 以保證任何 reader 都可讀到.
- commit-唯一: 以保證多個 reader 返回相同的結果.
- commit後不能修改: 以保證多次讀返回同樣的結果.
第一點就是寫quorum
第二與三點就需要能夠比較不同writer的手段(全序關係),所以寫入的值需要一個commit_index,讓reader知道要拿那個value
struct State {
log: Vec<{
commit_index: u64,
cmd: Cmd
}>,
}
paxos叫vrnd,raft叫term
剛剛是reader的,接著是writer的唯一與不可修改 會破壞writer的唯一與不可修改就是有沒有可能要寫之前有其他人要寫呢? 所以我們需要一個機制讓對方承諾說不會接受舊的寫入
所以就再多一個commit_index
struct Node {
commit_index: u64,
state: State,
}
paxos叫rnd,raft叫term與voteFor
這樣就有兩個phase
impl Node {
fn handle_phase_1(&mut self, p1_req: P1Req) {
let p1_reply = P1Reply{
commit_index: self.commit_index
state: self.state,
};
self.commit_index = max(self.commit_index, p1_req.commit_index());
return p1_reply;
}
}
impl Node {
fn handle_phase_2(&mut self, p2_req: P2Req) {
let p2_reply = P2Reply{
commit_index: self.commit_index
};
if p2_req.commit_index >= self.commit_index {
self.state.update(p2_req.state);
self.commit_index = max(self.commit_index, p2_req.commit_index);
}
return p2_reply;
}
}
注意到self.commit_index = max(self.commit_index, p2_req.commit_index)
這裡就是說node的commit_index一定大於等於state最後一個的commit_index
這邊也可以從writer的角度來看為什麼raft只能在自己的term做commit